





ResNet50 TensorFlow
LeaderGPU® is a brand new service that has entered GPU computing market with earnest intent for a good long while. The speed of calculations for the ResNet-50 model in LeaderGPU® is 2.5 times faster comparing to Google Cloud, and 2.9 times faster comparing to AWS (data is provided for an example with 8x GTX 1080 compared to 8x Tesla® K80). The cost of per-minute leasing of the GPU in LeaderGPU® starts from as little as 0.02 euros, which is more than 4 times lower than the cost of renting in Google Cloud and more than 5 times lower than the cost in AWS (as of July 7, 2017).
Throughout this article, we will be testing the ResNet-50 model in such popular services as LeaderGPU®, AWS and Google Cloud. You will be able to see in practice why LeaderGPU® significantly outperforms the represented competitors.
All tests were performed using python 3.5 and Tensorflow-gpu 1.2 on machines with GTX 1080, GTX 1080 TI and Tesla® P 100 with CentOS 7 operating system installed and CUDA® 8.0 library.
The following commands were used to run the test:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Number of cards on the server) --model resnet50 --batch_size 32 (64, 128, 256, 512)GTX 1080 instances
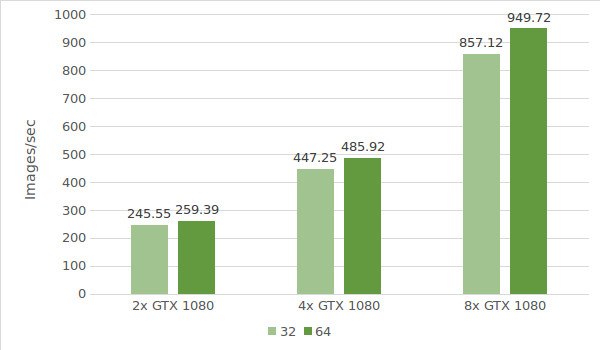
For the first test, we use instances with the GTX 1080. Testing environment data (with batch sizes 32 and 64) is provided below:
- Instance types:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Model:ResNet50
- Date of testing:June 2017
The test results are shown in the following diagram:
GTX 1080TI instances
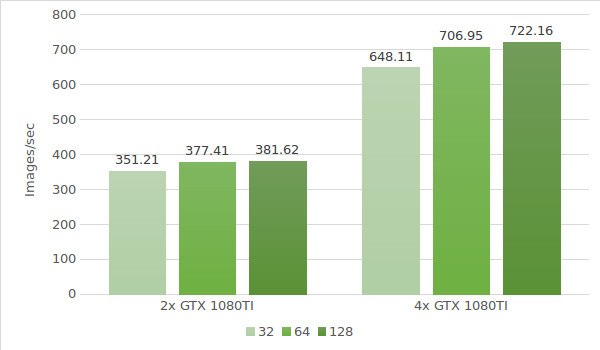
The next step is testing instances with the GTX 1080 Ti. Testing environment data (with batch sizes 32, 64 and 128) is provided below:
- Instance types:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Model:ResNet50
- Date of testing:June 2017
The test results are shown in the following diagram:
Tesla® P100 instance
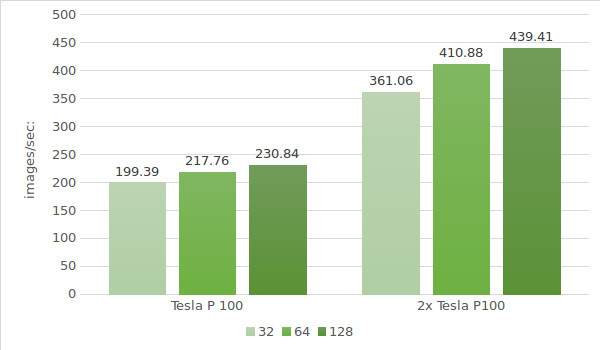
The final step is testing instances with Tesla® P100. Testing environment data is provided below (with batch sizes 32, 64 and 128):
- Instance type:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Model:ResNet50
- Date of testing:June 2017
The test results are shown in the following diagram:
The following table represents the Resnet50 test results for Google cloud and AWS (batch size 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
* Provided data was acquired from the following sources:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Let's calculate the cost and processing time for 1,000,000 images on each LeaderGPU®, AWS and Google machine. Counting is available with a batch size of 64 for all machines.
| GPU | Number of images | Time | Price (per minute) | Total cost |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0.03 | € 1.93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0.02 | € 0.69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0.11 | € 1.93 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0.02 | € 0.47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0.02 | € 0.81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0.0825** | € 3.55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0.107 | € 4.64 |
** The Google cloud service does not offer per minute payment plans. Per minute cost calculations are based on the hourly price ($ 5,645).
As can be concluded from the table, the image processing speed in the ResNet-50 model is the maximum with 8x GTX 1080 from LeaderGPU®, while:
The initial lease cost at LeaderGPU® starts from as little as € 0.02 per minute, which is about 4.13 times lower than in the instances of 8x Tesla® K80 by Google Cloud, and about 5.35 times lower than in the instances of 8x Tesla® K80 from Google AWS;
processing time was 17 minutes 32 seconds, which is 2.5 times faster than in the 8x Tesla® K80 instances from the Google Cloud, and 2.49 times faster than in the 8x Tesla® K80 instances from Google AWS.
LeaderGPU® significantly outperforms its competitors both in terms of service availability and image processing speed. Rent a GPU with a per-minute payment in LeaderGPU® to solve various tasks in the shortest time!