





Índice de referencia ResNet-50 en Tensorflow™
LeaderGPU® es un servicio nuevo que ha entrado en el mercado de la computación por GPU con serias intenciones a largo plazo. La velocidad de los cálculos del modelo ResNet-50 en LeaderGPU® es 2,5 veces más rápida en comparación con Google Cloud y 2,9 veces más rápida en comparación con AWS (datos relativos a un ejemplo con 8x GTX 1080 en comparación con 8x Tesla® K80). El precio del alquiler por minuto de GPU en LeaderGPU® comienza desde tan solo 0,02 euros, que es más de 4 veces más bajo que el precio del alquiler en Google Cloud y más de 5 veces más bajo que el precio en AWS (al 7 de julio de 2017).
En este artículo, probaremos el modelo ResNet-50 en servicios populares como LeaderGPU®, AWS y Google Cloud. Podrá ver en la práctica el motivo por el que LeaderGPU® supera considerablemente a los competidores representados.
Todas las pruebas se realizaron utilizando Python 3.5 y Tensorflow-gpu 1.2 en máquinas con GTX 1080, GTX 1080 TI y Tesla® P 100 con sistema operativo CentOS 7 instalado y biblioteca CUDA® 8.0.
Se utilizaron los siguientes comandos para ejecutar las pruebas:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Número de tarjetas en el servidor) --model resnet50 --batch_size 32 (64, 128, 256, 512)Instancias de GTX 1080
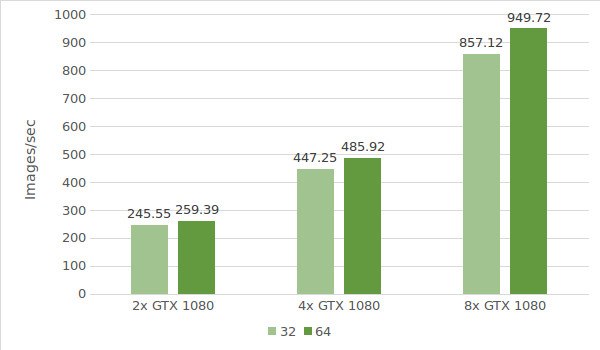
Para la primera prueba, utilizamos instancias con GTX 1080. Los datos del entorno de prueba (con tamaños de lote 32 y 64) se indican a continuación:
- Tipos de instancias:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modelo:ResNet50
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
Instancias de GTX 1080TI
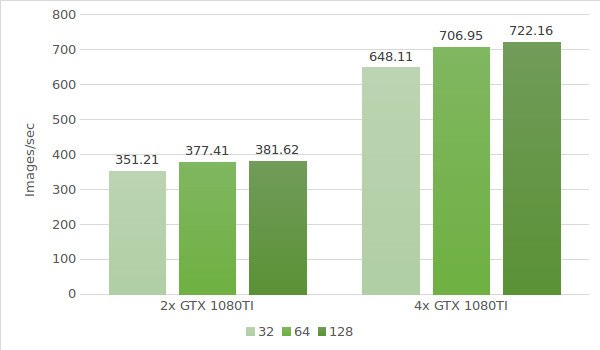
El siguiente paso es probar las instancias con GTX 1080 Ti. Los datos del entorno de prueba (con tamaños de lote 32, 64 y 128) se indican a continuación:
- Tipos de instancias:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modelo:ResNet50
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
Instancias de Tesla® P100
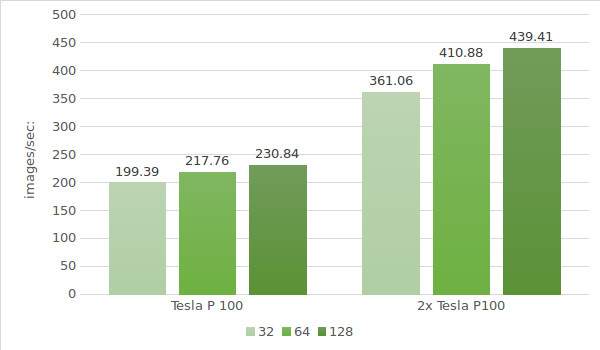
El paso final es probar las instancias con Tesla® P100. Los datos del entorno de prueba (con tamaños de lote 32, 64 y 128) se indican a continuación:
- Tipo de instancia:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Modelo:ResNet50
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
En el siguiente cuadro se presentan los resultados de las pruebas de Resnet50 en Google Cloud y AWS (tamaño de lote 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
* Los datos indicados se obtuvieron de las siguientes fuentes:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Calculemos el coste y el tiempo de procesamiento de 1 000 000 imágenes en cada máquina de LeaderGPU®, AWS y Google. El conteo está disponible con un tamaño de lote de 64 para todas las máquinas.
| GPU | Número de imágenes | Tiempo | Precio (por minuto) | Coste total |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0,03 | € 1,93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0,02 | € 0,69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0,10 | € 1,75 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0,02 | € 0,47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0,02 | € 0,81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0,0825** | € 3,55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0,107 | € 4,64 |
** El servicio Google Cloud no ofrece planes de pago por minuto. Los cálculos del precio por minuto se basan en el precio por hora (5645 $).
Sobre la base del cuadro, cabe concluir que la máxima velocidad de procesamiento de imágenes en el modelo ResNet-50 se obtiene con 8x GTX 1080 de LeaderGPU®, mientras que:
El precio inicial del alquiler en LeaderGPU® comienza desde tan solo € 0,02 por minuto, que es alrededor de 4,13 veces más bajo que el de las instancias de 8x Tesla® K80 ofrecidas por Google Cloud y alrededor de 5,35 veces más bajo que el de las instancias de 8x Tesla® K80 de AWS;
el tiempo de procesamiento fue de 17 minutos y 32 segundos, que es 2,5 veces más rápido que en las instancias de 8x Tesla® K80 de Google Cloud y 2,49 veces más rápido que en las instancias de 8x Tesla® K80 de AWS.
LeaderGPU® supera considerablemente a sus competidores tanto en términos de disponibilidad del servicio como de velocidad de procesamiento de imágenes. ¡Alquile una GPU con pago por minuto en LeaderGPU® para llevar a cabo diversas tareas en el menor tiempo!