





Test comparatif Tensorflow™ ResNet-50
LeaderGPU® est un tout nouveau service qui est entré sur le marché du calcul GPU avec une intention sérieuse de longue date. La vitesse des calculs pour le modèle ResNet-50 avec LeaderGPU® est 2,5 fois plus rapide par rapport à Google Cloud et 2,9 fois plus rapide par rapport à AWS (les données sont fournies pour un exemple avec 8x GTX 1080 par rapport à 8x Tesla® K80). Le coût de location à la minute du GPU sur LeaderGPU® commence à 0,02 euro seulement, ce qui est plus de 4 fois inférieur au coût de location de Google Cloud et plus de 5 fois inférieur au coût d’AWS (au 7 juillet 2017).
Tout au long de cet article, nous testerons le modèle ResNet-50 dans les services populaires LeaderGPU®, AWS et Google Cloud. Vous pourrez voir dans la pratique pourquoi LeaderGPU® surpasse de manière significative les concurrents représentés.
Tous les tests ont été effectués en utilisant Python 3.5 et Tensorflow-gpu 1.2 sur des machines configurées avec des cartes GTX 1080, GTX 1080 TI et Tesla® P100, le système d’exploitation CentOS 7 et la bibliothèque CUDA® 8.0.
Les commandes suivantes ont été utilisées pour exécuter les tests :
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Nombre de cartes sur le serveur) --model resnet50 --batch_size 32 (64, 128, 256, 512)Instances GTX 1080
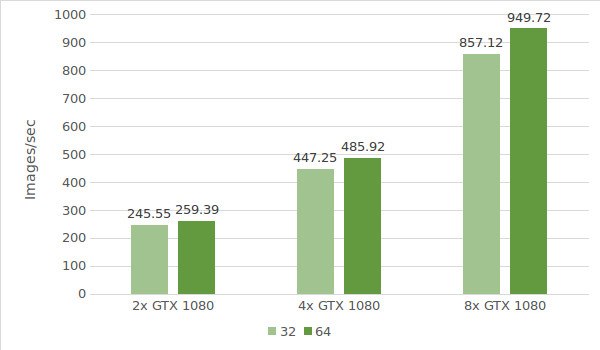
Pour le premier test, nous utilisons des instances avec la carte GTX 1080. Les données de l’environnement de test (avec les tailles de lot 32 et 64) sont fournies ci-dessous :
- Types d’instance :ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash :b1e174e
- Benchmark GitHub hash :9165a70
- Commande :
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modèle :ResNet50
- Date du test :Juin 2017
Les résultats du test sont présentés dans le diagramme suivant :'
Instances GTX 1080 Ti
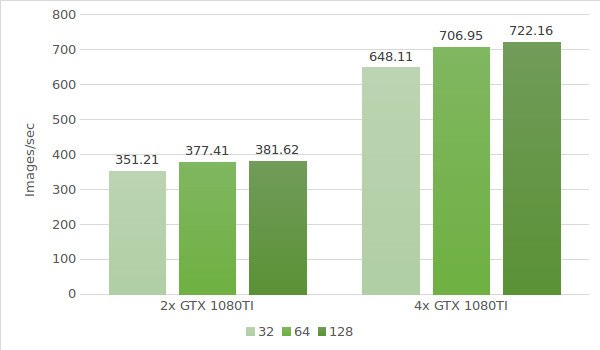
La prochaine étape consiste à tester des instances avec la carte GTX 1080 Ti. Les données de l’environnement de test (avec les tailles de lot 32, 64 et 128) sont fournies ci-dessous :
- Types d’instance :ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash :b1e174e
- Benchmark GitHub hash :9165a70
- Commande :
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modèle :ResNet50
- Date du test :Juin 2017
Les résultats du test sont présentés dans le diagramme suivant :'
Instance Tesla® P100
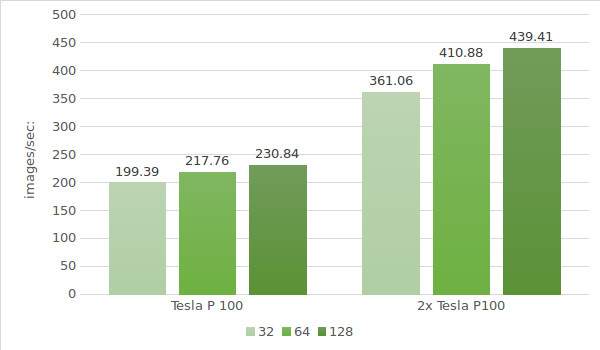
La dernière étape consiste à tester des instances avec la carte Tesla® P100. Les données de l’environnement de test sont fournies ci-dessous (avec les tailles de lot 32, 64 et 128) :
- Type d’instance :ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash :b1e174e
- Benchmark GitHub hash :9165a70
- Commande :
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Modèle :ResNet50
- Date du test :Juin 2017
Les résultats du test sont présentés dans le diagramme suivant :'
Le tableau suivant présente les résultats du test Resnet50 pour Google Cloud et AWS (taille de lot 64) :
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
* Les données fournies ont été extraites des sources suivantes :
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Calculons le coût et le temps de traitement de 1 000 000 d’images sur chaque machine LeaderGPU®, AWS et Google. Le comptage a été effectué avec une taille de lot de 64 pour toutes les machines.
| GPU | Nombre d’images | Temps | Prix (par minute) | Coût total |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0,03 | € 1,93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0,02 | € 0,69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0,10 | € 1,75 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0,02 | € 0,47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0,02 | € 0,81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0,0825** | € 3,55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0,107 | € 4,64 |
** Le service Google Cloud n’offre pas de plans de paiement à la minute. Les calculs de coût à la minute sont basés sur le prix horaire (5 645 $).
Comme on peut le conclure à partir du tableau, la vitesse de traitement d’image dans le modèle ResNet 50 est maximale avec 8x GTX 1080 de LeaderGPU®, tandis que :
le coût de location initial chez LeaderGPU® commence à seulement 0,02 € par minute, soit environ 4,13 fois moins que dans les instances de 8x Tesla® K80 de Google Cloud, et environ 5,35 fois moins que dans les instances de 8x Tesla® K80 de Google AWS ;
le temps de traitement était de 17 minutes 32 secondes, soit 2,5 fois plus rapide que dans les instances 8x Tesla® K80 de Google Cloud et 2,49 fois plus rapide que dans les instances 8x Tesla® K80 de Google AWS.
LeaderGPU® surpasse largement ses concurrents tant en termes de disponibilité du service que de vitesse de traitement des images. Louez un GPU avec un paiement à la minute sur LeaderGPU® pour résoudre diverses tâches dans les plus brefs délais !