





Benchmark Tensorflow™ ResNet-50
LeaderGPU® è un nuovo operatore del mercato del GPU computing, fermamente intenzionato a consolidarsi nel settore. La velocità di calcolo per il modello ResNet-50 su LeaderGPU® è superiore di 2,5 volte rispetto a Google Cloud e di 2,9 volte rispetto a AWS (dati relativi a un esempio con 8x GTX 1080 rispetto a 8x Tesla® K80). Su LeaderGPU®, il costo del leasing della GPU parte da 0,02 euro al minuto, una cifra inferiore di oltre 4 volte rispetto a Google Cloud e di oltre 5 volte rispetto a AWS (dati aggiornati al 7 luglio 2017).
In questo articolo vengono illustrati i risultati dei test per il modello ResNet-50 nei servizi offerti da LeaderGPU®, AWS e Google Cloud. Leggendo l'articolo, ti renderai conto dei motivi per cui le prestazioni di LeaderGPU® sono di gran lunga superiori a quelle dei concorrenti.
Tutti i test sono stati svolti utilizzando Python 3.5 e Tensorflow-gpu 1.2 su dispositivi con GTX 1080, GTX 1080 TI e Tesla® P 100, con sistema operativo CentOS 7 installato e libreria CUDA® 8.0.
Per il test sono stati utilizzanti i seguenti comandi:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Numero di schede sul server) --model resnet50 --batch_size 32 (64, 128, 256, 512)Istanze GTX 1080
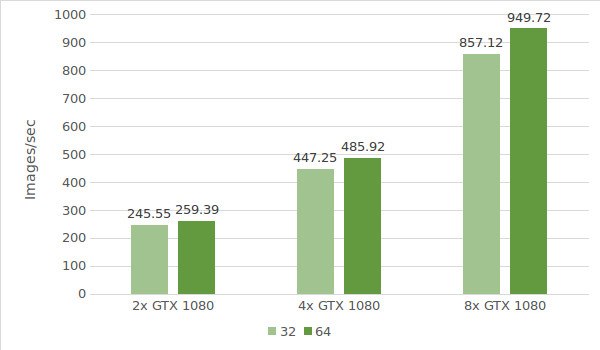
Per il primo test abbiamo utilizzato le istanze con GTX 1080. Seguono i dati dell'ambiente di test (con batch di dimensioni 32 e 64):
- Tipi di istanza:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modello:ResNet50
- Data del test:giugno 2017
I risultati del test sono indicati nel seguente grafico:
Istanze GTX 1080TI
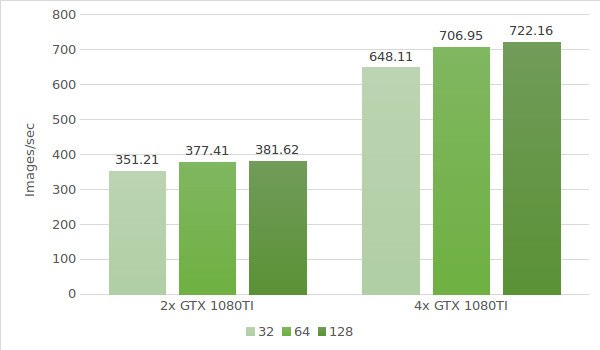
Abbiamo quindi testato le istanze con GTX 1080 Ti. Seguono i dati dell'ambiente di test (con batch di dimensioni 32, 64 e 128):
- Tipi di istanza:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modello:ResNet50
- Data del test:giugno 2017
I risultati del test sono indicati nel seguente grafico:
Istanza Tesla® P100
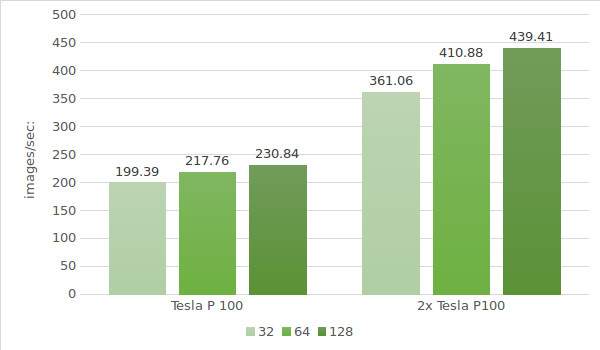
Per concludere, abbiamo testato le istanze con Tesla® P100. Ecco i dati dell'ambiente di test (con batch di dimensioni 32, 64 e 128):
- Tipo di istanza:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Modello:ResNet50
- Data del test:giugno 2017
I risultati del test sono indicati nel seguente grafico:
La seguente tabella mostra i risultati dei test su Resnet50 con Google Cloud e AWS (batch di dimensione 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
*I dati forniti sono stati recuperati dalle seguenti fonti:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Passiamo ora al calcolo dei costi e dei tempi di elaborazione di 1.000.000 di immagini su dispositivi con LeaderGPU®, AWS e Google. I dati sono relativi a un batch di dimensione 64 per tutti i dispositivi.
| GPU | Numero di immagini | Tempo | Prezzo al minuto | Costo totale |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0,03 | € 1,93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0,02 | € 0,69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0,10 | € 1,75 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0,02 | € 0,47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0,02 | € 0,81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0,0825** | € 3,55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0,107 | € 4,64 |
*Il servizio Google Cloud non offre piani di pagamento al minuto. Il costo al minuto è stato calcolato sulla base del prezzo orario ($5.645).
Come possiamo osservare nella tabella, la velocità di elaborazione delle immagini con il modello ResNet-50 è la più elevata su 8x GTX 1080 con LeaderGPU®. Inoltre:
il costo del leasing proposto da LeaderGPU® parte da €0,02 al minuto, inferiore di circa 4,13 volte rispetto alle istanze di 8x Tesla® K80 con Google Cloud e di circa 5,35 volte rispetto alle istanze di 8x Tesla® K80 con AWS;
la velocità di elaborazione è di 17 minuti e 32 secondi, superiore di 2,5 volte rispetto alle istanze di 8x Tesla® K80 con Google Cloud e di 2,49 volte rispetto alle istanze di 8x Tesla® K80 con AWS.
LeaderGPU® supera in maniera significativa i concorrenti in termini di disponibilità del servizio e velocità di elaborazione delle immagini. Noleggia una GPU con tariffa al minuto su LeaderGPU® per gestire svariate attività alla massima velocità!