





Tensorflow™ ResNet-50-benchmark
LeaderGPU® is een gloednieuwe dienst die de markt voor GPU-computers al geruime tijd serieus betreedt. De snelheid van de berekeningen voor het ResNet-50-model in LeaderGPU® is 2,5 keer sneller dan Google Cloud en 2,9 keer sneller dan AWS (gegevens worden verstrekt voor een voorbeeld met 8x GTX 1080 vergeleken met 8x Tesla® K80). De kosten voor het per minuut huren van de GPU in LeaderGPU® beginnen al vanaf € 0,02. Dat is meer dan 4 keer lager dan de kosten voor het huren bij Google Cloud en meer dan 5 keer lager dan de kosten bij AWS (per 7 juli, 2017).
In dit artikel testen wij het ResNet-50-model in populaire diensten zoals LeaderGPU®, AWS en Google Cloud. U zult in de praktijk kunnen zien waarom LeaderGPU® aanzienlijk beter presteert dan de vertegenwoordigde concurrenten.
Alle testen werden uitgevoerd met python 3.5 en Tensorflow-gpu 1.2 op machines met GTX 1080, GTX 1080 Ti en Tesla® P 100 met geïnstalleerd besturingssysteem CentOS 7 en CUDA® 8.0-bibliotheek.
De volgende commando's werden gebruikt om de test uit te voeren:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Aantal kaarten in de server) --model resnet50 --batch_size 32 (64, 128, 256, 512)GTX 1080-instanties
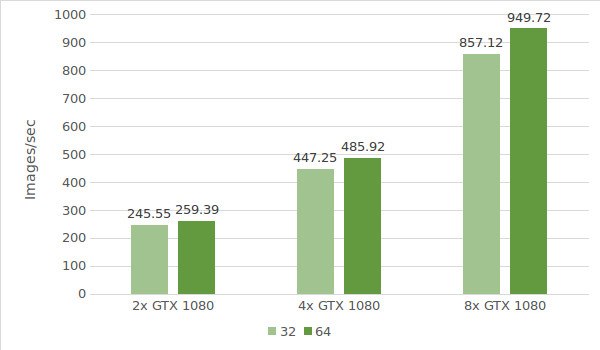
Voor de eerste test gebruiken we instanties met de GTX 1080. De testomgevinggegevens (met batchgroottes 32 en 64) staan hieronder:
- Typen instanties:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Model:ResNet50
- Testdatum:juni 2017
De testresultaten zijn weergegeven in het volgende diagram:
GTX 1080Ti-instanties
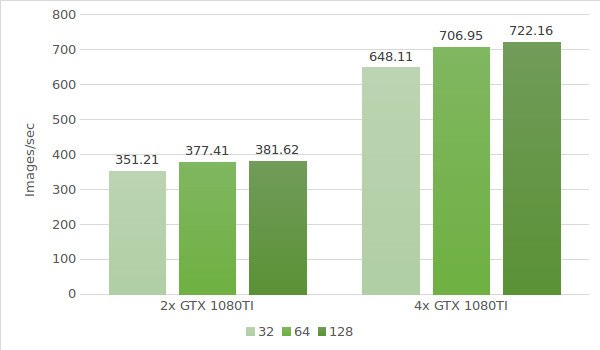
De volgende stap is het testen van instanties met de GTX 1080Ti. De testomgevinggegevens (met batchgroottes 32, 64 en 128) staan hieronder:
- Typen instanties:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Model:ResNet50
- Testdatum:juni 2017
De testresultaten zijn weergegeven in het volgende diagram:
Tesla® P100-instantie
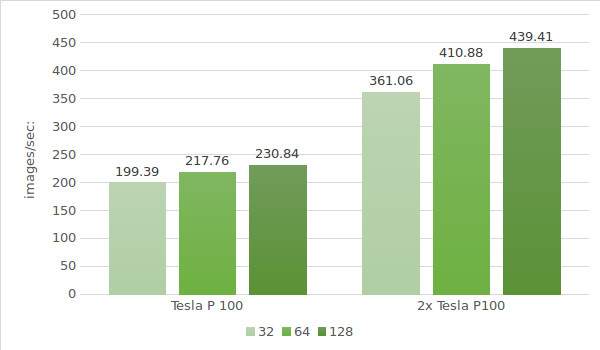
De laatste stap is testen van instanties met Tesla® P100. De testomgevinggegevens (met batchgroottes 32, 64 en 128) staan hieronder:
- Type instantie:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Model:ResNet50
- Testdatum:juni 2017
De testresultaten zijn weergegeven in het volgende diagram:
De volgende tabel toont de testresultaten van Resnet50 voor Google Cloud en AWS (batchgrootte 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
* De verstrekte gegevens zijn afkomstig uit de volgende bronnen:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Laten we de kosten en verwerkingstijd berekenen van 1.000.000 beelden op elke machine van LeaderGPU®, AWS en Google. Berekeningen zijn beschikbaar met een batchgrootte van 64 voor alle machines.
| GPU | Aantal beelden | Tijd | Prijs (per minuut) | Totale kosten |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0,03 | € 1,93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0,02 | € 0,69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0,10 | € 1,75 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0,02 | € 0,47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0,02 | € 0,81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0,0825** | € 3,55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0,107 | € 4,64 |
** De Google Cloud-dienst biedt geen betaalplannen per minuut. De berekening van de kosten per minuut is gebaseerd op de uurprijs ($ 5.645).
Zoals uit de tabel kan worden opgemaakt, is de beeldverwerkingssnelheid in het ResNet-50-model maximaal met 8x GTX 1080 van LeaderGPU®, waarbij:
de initiële leasekosten bij LeaderGPU® beginnen al vanaf € 0,02 per minuut. Dat is ongeveer 4,13 keer lager dan bij instanties van 8x Tesla® K80 van Google Cloud en ongeveer 5,35 keer lager dan bij instanties van 8x Tesla® K80 van AWS;
de verwerkingstijd 17 minuten 32 seconden bedroeg. Dat is 2,5 keer sneller dan in de instanties van 8x Tesla® K80 van Google Cloud en 2,49 keer sneller dan in de instanties van 8x Tesla® K80 van AWS.
LeaderGPU® presteert aanzienlijk beter dan zijn concurrenten, zowel wat betreft de beschikbaarheid van diensten als de snelheid van de beeldverwerking. Huur een GPU met een betaling per minuut in LeaderGPU® om verschillende taken in de kortste tijd op te lossen.