





Tensorflow™ – ResNet-50-Benchmark
LeaderGPU® ist ein brandneuer Dienst, der seit geraumer Zeit mit ernsten Absichten in den Markt für GPU-Computing eintritt. Die Geschwindigkeit der Berechnungen für das ResNet-50 Modell in LeaderGPU® ist 2,5-mal höher im Vergleich zu Google Cloud und 2,9-mal höher im Vergleich zu AWS (die Daten beziehen sich auf eine Beispielkonfiguration mit 8 GTX 1080 im Vergleich zu 8 Tesla® K80). Die Kosten für die Miete der GPUs in LeaderGPU® beginnen bei nur 0,02 Euro pro Minute, was mehr als 4-mal niedriger ist als die Kosten für die Miete in Google Cloud und mehr als 5-mal niedriger als die Kosten in AWS (Stand: 7. Juli 2017).
In diesem Artikel testen wir das ResNet-50-Modell in beliebten Diensten wie LeaderGPU®, AWS und Google Cloud. So können Sie anhand eines praktischen Beispiels sehen, warum LeaderGPU® die untersuchten Konkurrenten deutlich übertrifft.
Alle Tests wurden mit Python 3.5 und Tensorflow-gpu 1.2 auf Rechnern mit GTX 1080, GTX 1080 Ti und Tesla® P 100 mit dem CentOS 7-Betriebssystem und der CUDA® 8.0-Bibliothek durchgeführt.
Die folgenden Befehle wurden zur Durchführung des Tests verwendet:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Anzahl der Karten auf dem Server) --model resnet50 --batch_size 32 (64, 128, 256, 512)GTX 1080-Instanzen
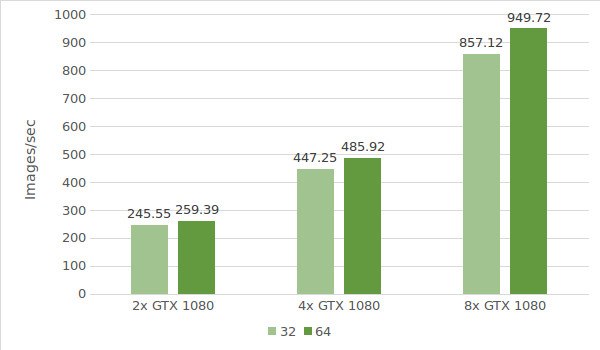
Für den ersten Test verwenden wir Instanzen mit GTX 1080. Die Daten der Testumgebung (mit den Stapelgrößen 32 und 64) sind unten aufgeführt:
- Instanztypen:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub Hash:b1e174e
- Benchmark GitHub Hash:9165a70
- Befehl:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modell:ResNet50
- Datum des Tests:Juni 2017
Die Testergebnisse sind in dem folgenden Diagramm dargestellt:
GTX 1080 Ti-Instanzen
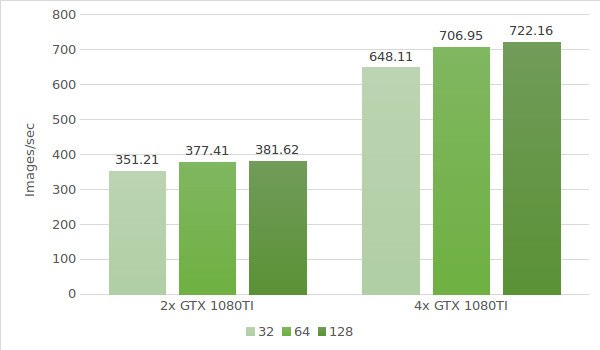
Im nächsten Schritt testen wir Instanzen mit GTX 1080 Ti. Die Daten der Testumgebung (mit den Stapelgrößen 32, 64 und 128) sind unten aufgeführt:
- Instanztypen:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub Hash:b1e174e
- Benchmark GitHub Hash:9165a70
- Befehl:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512) - Modell:ResNet50
- Datum des Tests:Juni 2017
Die Testergebnisse sind in dem folgenden Diagramm dargestellt:
Tesla® P100-Instanz
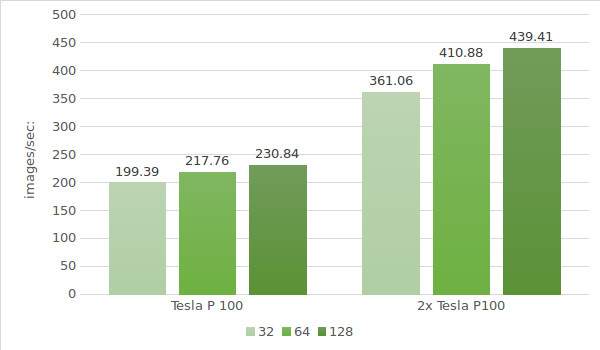
Zum Schluss werden Instanzen mit Tesla® P100 getestet. Die Daten der Testumgebung (mit den Stapelgrößen 32, 64 und 128) sind unten aufgeführt:
- Instanztyp:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub Hash:b1e174e
- Benchmark GitHub Hash:9165a70
- Befehl:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512) - Modell:ResNet50
- Datum des Tests:Juni 2017
Die Testergebnisse sind in dem folgenden Diagramm dargestellt:
Die folgende Tabelle zeigt die Resnet50-Testergebnisse für Google Cloud und AWS (Stapelgröße 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 51.9 | 51.5 |
| 2x Tesla K80 | 99 | 98 |
| 4x Tesla K80 | 195 | 195 |
| 8x Tesla K80 | 387 | 384 |
* Die bereitgestellten Daten stammen aus den folgenden Quellen:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Berechnen wir nun die Kosten und die Verarbeitungszeit von 1.000.000 Bildern auf einem LeaderGPU®-, AWS- und Google-Rechner. Das Zählen ist bei einer Stapelgröße von 64 auf allen Rechnern möglich.
| GPU | Anzahl der Bilder | Zeit | Preis (pro Minute) | Gesamtkosten |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | € 0,03 | € 1,93 |
| 4x GTX 1080 | 1000000 | 34m 17sec | € 0,02 | € 0,69 |
| 8x GTX 1080 | 1000000 | 17m 32sec | € 0,10 | € 1,75 |
| 4x GTX 1080TI | 1000000 | 23m 34sec | € 0,02 | € 0,47 |
| 2х Tesla P100 | 1000000 | 40m 33sec | € 0,02 | € 0,81 |
| 8x Tesla K80 Google cloud | 1000000 | 43m 3sec | € 0,0825** | € 3,55 |
| 8x Tesla K80 AWS | 1000000 | 43m 24sec | € 0,107 | € 4,64 |
** Der Google Cloud-Dienst bietet keine minutenbasierten Zahlungspläne an. Die Berechnung der Kosten pro Minute basiert auf dem Stundenpreis (5,645 $).
Wie aus der Tabelle hervorgeht, ist die Bildverarbeitungsgeschwindigkeit im ResNet-50-Modell mit 8 GTX 1080 in LeaderGPU® am höchsten. Hinzu kommt:
Die anfänglichen Mietkosten liegen bei LeaderGPU® bei nur 0,02 € pro Minute, was etwa 4,13-mal niedriger ist als bei den Instanzen mit 8 Tesla® K80 in Google Cloud und etwa 5,35-mal niedriger als bei den Instanzen mit 8 Tesla® K80 in AWS.
Die Verarbeitungszeit betrug 17 Minuten und 32 Sekunden, was 2,5-mal schneller ist als bei den Instanzen mit 8 Tesla® K80 in Google Cloud und 2,49-mal schneller als bei den Instanzen mit 8 Tesla® K80 in AWS.
LeaderGPU® übertrifft seine Konkurrenten sowohl in Bezug auf die Serviceverfügbarkeit als auch auf die Bildverarbeitungsgeschwindigkeit deutlich. Mieten Sie eine GPU mit einer minutenweisen Abrechnung in LeaderGPU®, um verschiedene Aufgaben in kürzester Zeit zu lösen!