





Vérifiez NVLink sous Windows
Veuillez noter que vous devez Installer les pilotes Nvidia sous Windows ou Installer CUDA toolkit sous Windows avant de vérifier les connexions NVLink. Aussi, basculez le mode GPU en TCC.
Installer Visual Studio
Assurons-nous que tout fonctionne correctement en exécutant cuda-samples du dépôt officiel. Pour ce faire, nous devons installer séquentiellement Visual Studio 2022 CE (Community Edition) et réinstaller CUDA Toolkit pour activer les plugins VS. Visitez https://visualstudio.microsoft.com/downloads/ pour télécharger Visual Studio 2022 :

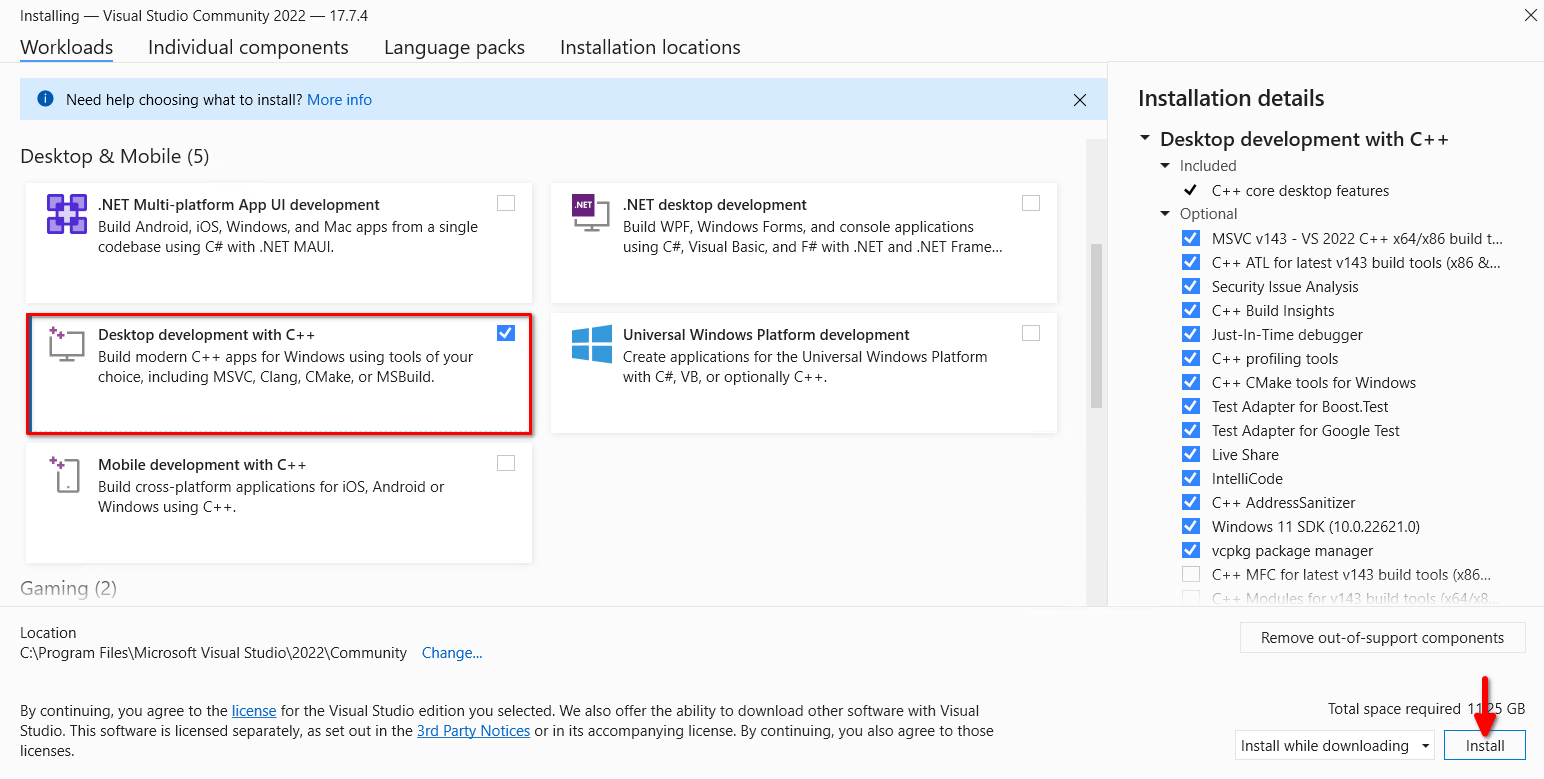
Exécutez l'installateur téléchargé, cochez Développement de bureau avec C++, et cliquez sur le bouton Installer :
Exécuter des tests
Réinstallez CUDA toolkit en utilisant notre guide étape par étape Installer CUDA toolkit sous Windows. Redémarrez le serveur et téléchargez l'archive ZIP avec cuda-samples. Décompressez-le et ouvrez le sous-répertoire Samples\1_Utilities\bandwidthTest. Double-cliquez sur bandwidthTest_vs2022 et lancez-le en utilisant le raccourci clavier Ctrl + F5 :
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA RTX A6000
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.0
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.6
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 637.2
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
Vous pouvez exécuter n'importe quel échantillon. Essayez Samples\5_Domain_Specific\p2pBandwidthLatencyTest pour voir votre topologie et votre matrice de connectivité :
[P2P (Peer-to-Peer) GPU Bandwidth Latency Test]
Device: 0, NVIDIA RTX A6000, pciBusID: 3, pciDeviceID: 0, pciDomainID:0
Device: 1, NVIDIA RTX A6000, pciBusID: 4, pciDeviceID: 0, pciDomainID:0
Device=0 CAN Access Peer Device=1
Device=1 CAN Access Peer Device=0
***NOTE: In case a device doesn't have P2P access to other one, it falls back to normal memcopy procedure.
So you can see lesser Bandwidth (GB/s) and unstable Latency (us) in those cases.
P2P Connectivity Matrix
D\D 0 1
0 1 1
1 1 1
Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1
0 671.38 6.06
1 6.06 671.47
Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)
D\D 0 1
0 631.31 52.73
1 52.83 673.00
Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1
0 645.00 8.19
1 8.11 677.87
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1
0 655.96 101.78
1 101.70 677.92
P2P=Disabled Latency Matrix (us)
GPU 0 1
0 2.20 49.07
1 10.33 2.20
CPU 0 1
0 3.55 7.01
1 6.79 3.39
P2P=Enabled Latency (P2P Writes) Matrix (us)
GPU 0 1
0 2.19 1.33
1 1.26 2.22
CPU 0 1
0 6.80 4.86
1 2.09 3.02
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
Publié: 07.05.2024