





VGG16 TensorFlow
LeaderGPU® - a revolutionary service that allows you to approach GPU-computing from a new angle. The calculations speed for the VGG16 model in LeaderGPU® is 1.8 times faster comparing to Google Cloud, and 1.7 times faster comparing to AWS (the data is given for an example with 8x GTX 1080). The cost of per-minute leasing of the GPU in LeaderGPU® starts from as little as 0.02 euros, which is more than 4 times lower than the cost of renting in Google Cloud and more than 5 times lower than the cost in AWS (as of July 7, 2017).
Throughout this article, we will be testing the VGG16 model in various services offering GPUs rental services, including LeaderGPU®, AWS and Google Cloud.Tests outcome show why LeaderGPU® is the most profitable offer among the considered options.
All tests were performed using python 3.5 and Tensorflow-gpu 1.2 on machines with GTX 1080, GTX 1080 TI and Tesla® P 100 with CentOS 7 operating system installed and the CUDA® 8.0 library installed.
The following commands were used to run the test:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2(Number of cards on the server) --model vgg16 --batch_size 32 (64)GTX 1080 instances
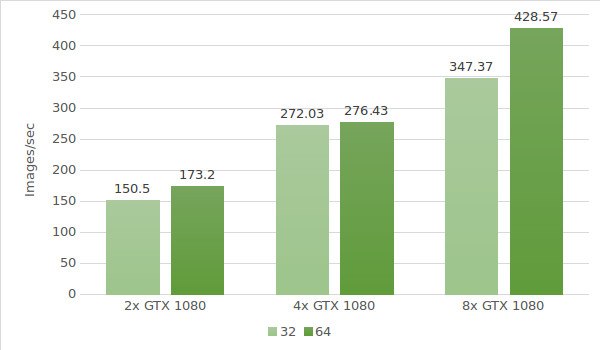
In the first test we use instances with GTX 1080 Testing environment data (with batch sizes 32 and 64) is provided below:
Testing environment:
- Instance types:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model vgg16 --batch_size 32 (optional 64) - Model:VGG16
- Date of testing:June 2017
The test results are shown in the following diagram:
GTX 1080TI instances
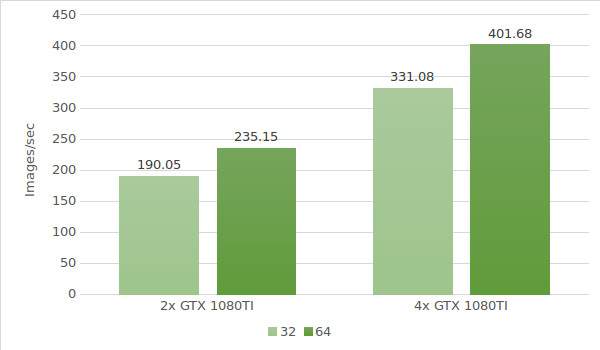
Now let's test instances with the GTX 1080 Ti Testing environment data (with batch sizes 32 and 64) is provided below:
Testing environment:
- Instance types:ltbv21, ltbv18
- GPU:2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model vgg16 --batch_size 32 (optional 64) - Model:VGG16
- Date of testing:June 2017
The test results are shown in the following diagram:
Tesla® P100 instance
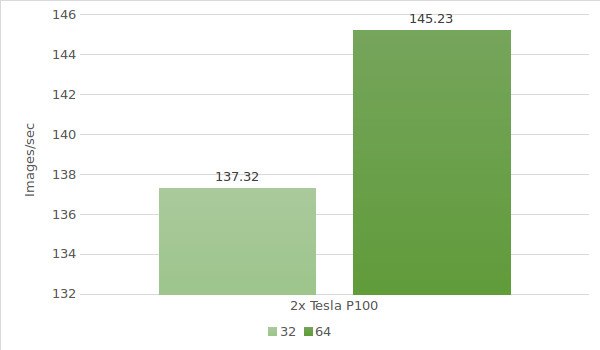
Finally, it's time to test the instances with Tesla® P100. In this case, the testing environment will be the following (with batch sizes 32 and 64):
Testing environment:
- Instance type:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model vgg16 --batch_size 32 (optional 64) - Model:VGG16
- Date of testing:June 2017
The test results are shown in the following diagram:
The table below shows the results of the VGG16 tests on Google Cloud and AWS:
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 35.4 | 36.3 |
| 2x Tesla K80 | 64.8 | 69.4 |
| 4x Tesla K80 | 120 | 141 |
| 8x Tesla K80 | 234 | 260 |
* Data obtained from the following sources:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
We will calculate the cost and processing time of 1,000,000 images on each LeaderGPU®, AWS and Google machine (calculation based on the highest outcome of each machine):
| GPU | Number of images | Time | Cost (per minute) | Total cost |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 96m 13sec | € 0.03 | € 2.89 |
| 4x GTX 1080 | 1000000 | 60m 17sec | € 0.02 | € 1.21 |
| 8x GTX 1080 | 1000000 | 38m 53sec | € 0.11 | € 4.28 |
| 4x GTX 1080TI | 1000000 | 41m 29sec | € 0.02 | € 0.83 |
| 2х Tesla P100 | 1000000 | 114m 45sec | € 0.02 | € 2.30 |
| 8x Tesla K80 Google cloud | 1000000 | 71m 12sec | € 0.0825** | € 4.84 |
| 8x Tesla K80 AWS | 1000000 | 64m 6sec | € 0.107 | € 6.85 |
** The Google cloud service does not offer per minute payment plans. Per minute cost calculations are based on the hourly price ($ 5,645).
As seen from the table, the image processing speed in VGG16 model is the maximum on 8x GTX 1080 from LeaderGPU®, while:
The initial lease cost at LeaderGPU® starts from as little as € 0.02 per minute, which is about 4.13 times lower than in the instances of 8x Tesla® K80 by Google Cloud, and about 5.35 times lower than in the instances of 8x Tesla® K80 from Google AWS;
processing time was 38 minutes 53 seconds, which is 1.8 times faster than in the instances of 8x Tesla® K80 from the Google Cloud, and 1.7 times faster than in the instances of 8x Tesla® K80 from Google AWS.
All this suggests that LeaderGPU® is much more profitable than its competitors, allowing to achieve maximum speed for optimal money. Hire the best GPU with flexible pricing policy in LeaderGPU® today!