





Inception TensorFlow
LeaderGPU® is an ambitious player in the GPU computing market intend to change the current state of affairs. According on tests results, the computation speed for the Inception v3 model in LeaderGPU® is 3 times faster comparing to Google Cloud, and in 2.9 times faster comparing to AWS (data is provided with respect to example with 8x GTX 1080). The cost of per-minute leasing of the GPU in LeaderGPU® starts from as little as 0.02 euros, which is more than 4 times lower than the cost of renting in Google Cloud and more than 5 times lower than the cost in AWS (as of July 7).
Throughout this article, we will be testing the Inception v3 model in such services as LeaderGPU®, AWS, and Google Cloud. We will determine why LeaderGPU® is the leading offer among the considering options.
All tests were performed using python 3.5 and Tensorflow-gpu 1.2 on machines with GTX 1080, GTX 1080 TI and Tesla® P 100 with CentOS 7 operating system installed and CUDA® 8.0 library.
The following commands were used to run the tests:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2(Number of cards on the server) --model inception3 --batch_size 32 (64, 128)GTX 1080 instances
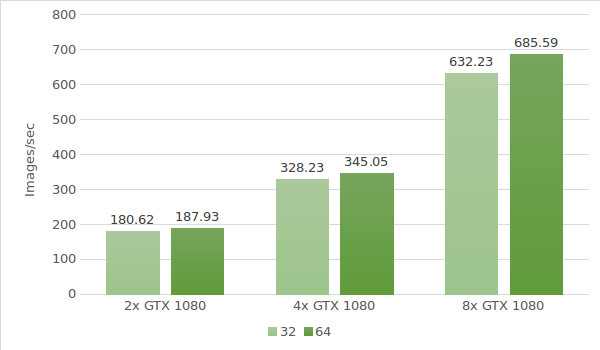
For the first test, we use instances with the GTX 1080. Testing environment data (with batch sizes 32 and 64) is provided below:
- Instance types:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model inception3 –batch size 32 (optional 64) - Model:Inception v3
- Date of testing:June 2017
The test results are shown in the following diagram:
GTX 1080TI instances
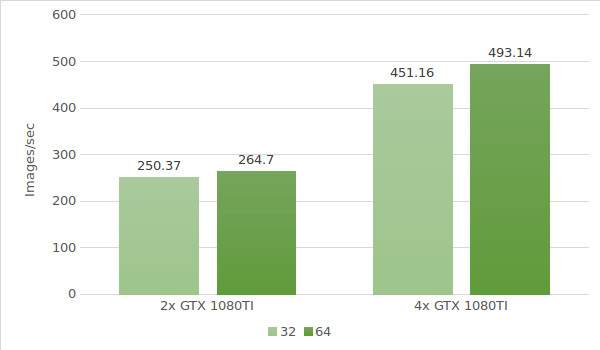
Now let's use instances with the GTX 1080 Ti. Testing environment data (with batch sizes 32 and 64) is provided below:
- Instance types:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model inception3 --batch_size 32 (optional 64, 128) - Model:Inception v3
- Date of testing:June 2017
The test results are shown in the following diagram:
Tesla® P100 instance
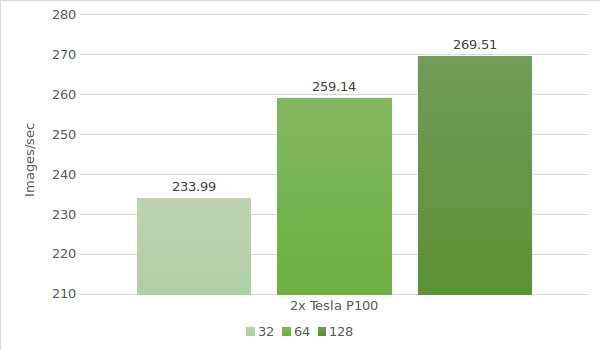
Finally, it's time to test the model with the Tesla® P100. Testing environment data (with batch sizes 32, 64 and 128) is provided below:
- Instance types:ltbv20
- GPU:GPU: 2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Command:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model inception3 –batch size 32 (optional 64, 128) - Model:Inception v3
- Date of testing:June 2017
The test results are shown in the following diagram:
In the table below, we collected the results of inception v3 tests on Google cloud and AWS (with the batch size 64)
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 30.5 | 30.8 |
| 2x Tesla K80 | 57.8 | 58.7 |
| 4x Tesla K80 | 116 | 117 |
| 8x Tesla K80 | 227 | 230 |
* Data for the table is quoted from the following sources:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Let's make a calculation of the cost and processing time for 1,000,000 images on each LeaderGPU®, AWS and Google machine. Counting was carried out with a batch size of 64 for all machines.
| GPU | Number of images | Time | Cost (per minute) | Total cost |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 88m 41sec | € 0.03 | € 2.66 |
| 4x GTX 1080 | 1000000 | 48m 18sec | € 0.02 | € 0.97 |
| 8x GTX 1080 | 1000000 | 24m 18sec | € 0.11 | € 2.67 |
| 4x GTX 1080TI | 1000000 | 33m 47sec | € 0.02 | € 0.68 |
| 2х Tesla P100 | 1000000 | 64m 18sec | € 0.02 | € 1.29 |
| 8x Tesla K80 Google cloud | 1000000 | 73m 25sec | € 0.0825** | € 6.05 |
| 8x Tesla K80 AWS | 1000000 | 72m 27sec | € 0.107 | € 7.75 |
** The Google cloud service does not offer per minute payment plans. Per minute cost calculations are based on the hourly price ($ 5,645).
As can be concluded from the table, the speed of image processing in the Inception v3 model is the maximum with 8x GTX 1080 from LeaderGPU®, while:
The initial cost in LeaderGPU® starts from as little as € 1.77, which is about 3.42 times lower than in the instances of 8x Tesla® K80 by Google Cloud, and about 4.38 times lower than in instances of 8x Tesla® K80 from Google AWS;
processing time was 24 minutes 18 seconds, which is 3.03 times faster than in the instances of 8x Tesla® K80 from the Google Cloud, and 2.99 times faster than in the 8x Tesla® K80 instances from Google AWS.
Testing results leave no doubts. LeaderGPU® is a proven leader in the field of GPU-computing, offering unrivaled solutions at reasonable prices. Take advantage of the cost-effective GPU offer from LeaderGPU® today!