





Índice de referencia Inception v3 en Tensorflow™
LeaderGPU® es un actor ambicioso en el mercado de la computación por GPU que pretende cambiar la situación actual. Según los resultados de las pruebas, la velocidad de los cálculos del modelo Inception v3 en LeaderGPU® es 3 veces más rápida en comparación con Google Cloud y 2,9 veces más rápida en comparación con AWS (datos relativos a un ejemplo con 8x GTX 1080). El precio del alquiler por minuto de GPU en LeaderGPU® comienza desde tan solo 0,02 euros, que es más de 4 veces más bajo que el precio del alquiler en Google Cloud y más de 5 veces más bajo que el precio en AWS (al 7 de julio).
En este artículo, probaremos el modelo Inception v3 en servicios como LeaderGPU®, AWS y Google Cloud. Determinaremos el motivo por el que LeaderGPU® es la oferta líder entre las opciones examinadas.
Todas las pruebas se realizaron utilizando Python 3.5 y Tensorflow-gpu 1.2 en máquinas con GTX 1080, GTX 1080 TI y Tesla® P 100 con sistema operativo CentOS 7 instalado y biblioteca CUDA® 8.0.
Se utilizaron los siguientes comandos para ejecutar las pruebas:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2(Número de tarjetas en el servidor) --model inception3 --batch_size 32 (64, 128)Instancias de GTX 1080
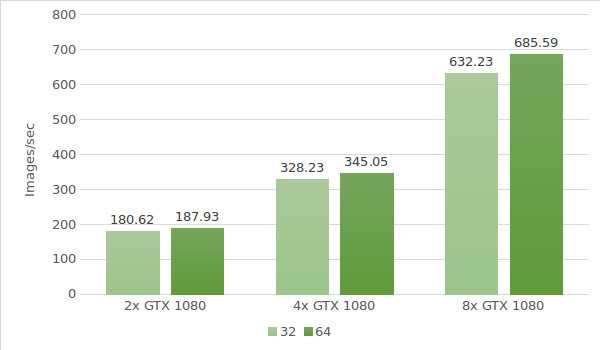
Para la primera prueba, utilizamos instancias con GTX 1080. Los datos del entorno de prueba (con tamaños de lote 32 y 64) se indican a continuación:
- Tipos de instancias:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model inception3 –batch size 32 (optional 64) - Modelo:Inception v3
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
Instancias de GTX 1080TI
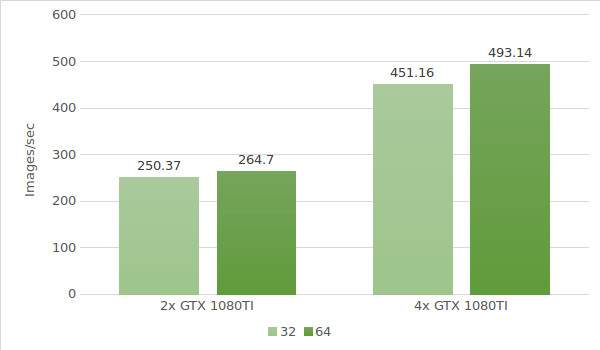
Ahora utilicemos instancias con GTX 1080 Ti. Los datos del entorno de prueba (con tamaños de lote 32 y 64) se indican a continuación:
- Tipos de instancias:ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model inception3 --batch_size 32 (optional 64, 128) - Modelo:Inception v3
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
Instancias de Tesla® P100
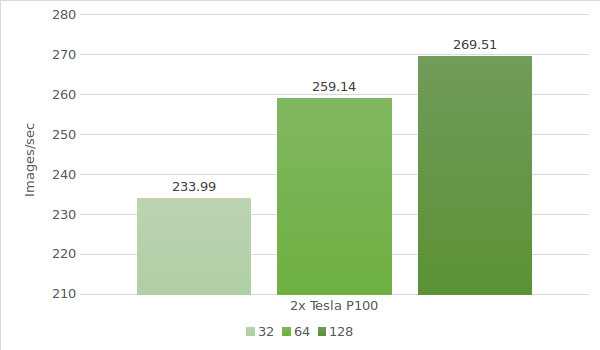
Por último, es hora de probar el modelo con Tesla® P100. Los datos del entorno de prueba (con tamaños de lote 32, 64 y 128) se indican a continuación:
- Tipos de instancias:ltbv20
- GPU:GPU: 2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Comando:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model inception3 –batch size 32 (optional 64, 128) - Modelo:Inception v3
- Fecha de la prueba:junio de 2017
Los resultados de la prueba se muestran en el diagrama siguiente:
En el cuadro a continuación hemos recogido los resultados de las pruebas con Inception v3 en Google Cloud y AWS (con tamaño de lote 64)
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 30.5 | 30.8 |
| 2x Tesla K80 | 57.8 | 58.7 |
| 4x Tesla K80 | 116 | 117 |
| 8x Tesla K80 | 227 | 230 |
* Los datos del cuadro se extrajeron de las siguientes fuentes:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Hagamos un cálculo del coste y del tiempo de procesamiento de 1 000 000 imágenes en cada máquina de LeaderGPU®, AWS y Google. El conteo se realizó con un tamaño de lote de 64 para todas las máquinas.
| GPU | Número de imágenes | Tiempo | Coste (por minuto) | Coste total |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 88m 41sec | € 0,03 | € 2,66 |
| 4x GTX 1080 | 1000000 | 48m 18sec | € 0,02 | € 0,97 |
| 8x GTX 1080 | 1000000 | 24m 18sec | € 0,10 | € 2,43 |
| 4x GTX 1080TI | 1000000 | 33m 47sec | € 0,02 | € 0,68 |
| 2х Tesla P100 | 1000000 | 64m 18sec | € 0,02 | € 1,29 |
| 8x Tesla K80 Google cloud | 1000000 | 73m 25sec | € 0,0825** | € 6,05 |
| 8x Tesla K80 AWS | 1000000 | 72m 27sec | € 0,107 | € 7,75 |
** El servicio Google Cloud no ofrece planes de pago por minuto. Los cálculos del precio por minuto se basan en el precio por hora (5645 $).
Sobre la base del cuadro, cabe concluir que la máxima velocidad de procesamiento de imágenes en el modelo Inception v3 se obtiene con 8x GTX 1080 de LeaderGPU®, mientras que:
El precio inicial en LeaderGPU® comienza desde tan solo 1,77 €, que es alrededor de 3,42 veces más bajo que el de las instancias de 8x Tesla® K80 ofrecidas por Google Cloud y alrededor de 4,38 veces más bajo que el de las instancias de 8x Tesla® K80 de AWS;
el tiempo de procesamiento fue de 24 minutos y 18 segundos, que es 3,03 veces más rápido que en las instancias de 8x Tesla® 8x de Google Cloud y 2,99 veces más rápido que en las instancias de 8x Tesla® K80 de AWS.
Los resultados de las pruebas no dejan lugar a dudas. LeaderGPU® es un líder consolidado del sector de la computación por GPU y ofrece soluciones inigualables a precios razonables. ¡Aproveche hoy mismo la oferta de GPU rentables de LeaderGPU®!