





Tensorflow™ Alexnet-benchmark
LeaderGPU®-diensten gericht op het veranderen van de regels van de GPU-computermarkt. De kenmerkende LeaderGPU®-eigenschappen tonen de verbazingwekkende snelheid van de berekeningen voor het Alexnet-model: 2,3 keer sneller dan in Google Cloud en 2,2 keer sneller dan in de AWS (gegevens zijn gegeven voor 8x GTX 1080). De kosten van de huur per minuut van de GPU bij LeaderGPU® beginnen vanaf € 0,02, 4,1 keer lager dan bij Google Cloud en 5,35 keer lager dan bij AWS (per 7 juli, 2017).
In dit artikel geven wij testresultaten voor het Alexnet-model in diensten zoals LeaderGPU®, AWS en Google Cloud. U zult begrijpen waarom LeaderGPU® de beste keuze is voor alle GPU-rekenbehoeften.
Alle betrokken testen werden uitgevoerd met python 3.5 en Tensorflow-gpu 1.2 op machines met GTX 1080, GTX 1080 Ti en Tesla® P 100 met geïnstalleerd besturingssysteem CentOS 7 en CUDA® 8.0-bibliotheek.
De volgende commando's werden gebruikt om de test uit te voeren:
# git clone https://github.com/tensorflow/benchmarks.git# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Aantal kaarten in de server) --model alexnet --batch_size 32 (64, 128, 256, 512)GTX 1080-instanties
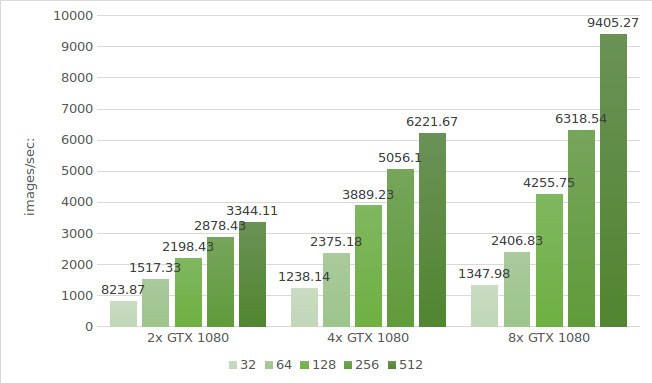
De eerste testen van het Alexnet-model worden uitgevoerd met de instanties van de GTX 1080. De testomgevinggegevens (met batchgroottes 32, 64, 128, 256 en 512) staan hieronder:
Testomgeving
- Typen instanties:ltbv17, ltbv13, ltbv16
- GPU: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model alexnet --batch_size 32 (optional 64, 128,256, 512) - Model:Alexnet
- Testdatum:juni 2017
De testresultaten worden in onderstaand diagram weergegeven:
GTX 1080Ti-instanties
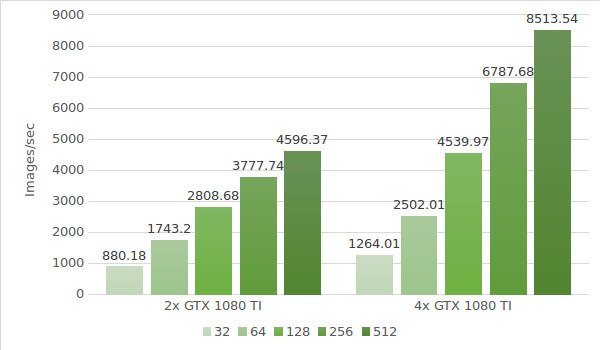
De volgende stap is het testen van het Alexnet-model met de instanties van de GTX 1080Ti. De testomgevinggegevens (met batchgroottes 32, 64, 128, 256 en 512) staan hieronder:
- Typen instanties:ltbv21, ltbv18
- GPU:2x GTX 1080TI, 4x GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model alexnet --batch_size 32 (optional 64, 128,256, 512) - Model:Alexnet
- Testdatum:juni 2017
De testresultaten worden in onderstaand diagram weergegeven:
Tesla® P100-instantie
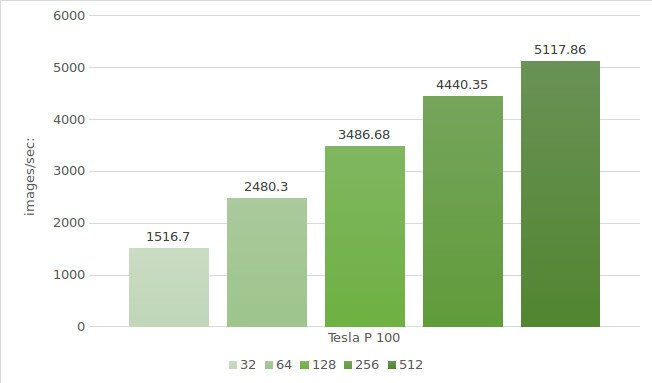
Ten slotte is het tijd om het Alexnet-model te testen met de Tesla® P100-instanties. De testomgeving (met batchgroottes 32, 64, 128, 256 en 512) ziet er als volgt uit:
- Type instantie:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub hash:b1e174e
- Benchmark GitHub hash:9165a70
- Opdracht:
# python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model alexnet --batch_size 32 (optional 64, 128, 256, 512) - Model:Alexnet
- Testdatum:juni 2017
De testresultaten worden in onderstaand diagram weergegeven:
Vergelijkbare Alexnet-testen in Google Cloud en AWS lieten de volgende resultaten zien:
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla K80 | 656 | 684 |
| 2x Tesla K80 | 1209 | 1244 |
| 4x Tesla K80 | 2328 | 2479 |
| 8x Tesla K80 | 4640 | 4853 |
* De verstrekte gegevens zijn afkomstig uit de volgende bronnen:
https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Laten we nu de kosten en verwerkingstijd berekenen van 1.000.000 beelden op elke machine van LeaderGPU®, AWS en Google. De berekening werd gemaakt op basis van het hoogste resultaat van elke machine.
| GPU | Aantal beelden | Tijd | Kosten (per minuut) | Totale kosten |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 5m | € 0,03 | € 0,15 |
| 4x GTX 1080 | 1000000 | 2m 40sec | € 0,02 | € 0,05 |
| 8x GTX 1080 | 1000000 | 1m 46sec | € 0,10 | € 0,18 |
| 4x GTX 1080TI | 1000000 | 2m 5sec | € 0,02 | € 0,04 |
| 2х Tesla P100 | 1000000 | 3m 15sec | € 0,02 | € 0,07 |
| 8x Tesla K80 Google cloud | 1000000 | 3m 35sec | € 0,0825** | € 0,29 |
| 8x Tesla K80 AWS | 1000000 | 3m 26sec | € 0,107 | € 0,36 |
** De Google Cloud-dienst biedt geen betaalplannen per minuut. De berekening van de kosten per minuut is gebaseerd op de uurprijs ($ 5.645).
Zoals uit de tabel kan worden opgemaakt, heeft de beeldverwerkingssnelheid in het VGG16-model het hoogste resultaat op 8x GTX 1080 van LeaderGPU®, waarbij:
de initiële leasekosten bij LeaderGPU® al beginnen vanaf € 1,92. Dat is ongeveer 2,5 keer lager dan bij instanties van 8x Tesla® K80 van Google Cloud, en ongeveer 3,6 keer lager dan bij instanties van 8x Tesla® K80 van AWS;
de verwerkingstijd 38 minuten 53 seconden bedroeg. Dat is 1,8 keer sneller dan bij de instanties van 8x Tesla® K80 van Google Cloud en 1,7 keer sneller dan bij de instanties van 8x Tesla® K80 van AWS.
Op basis van deze feiten kan worden geconcludeerd dat LeaderGPU® veel winstgevender is dan zijn concurrenten. Bij LeaderGPU® kan maximale snelheid tegen optimale prijzen worden bereikt. Huur vandaag nog de beste GPU met flexibele prijskaartjes bij LeaderGPU®.