





Qwen 2 vs Llama 3

Large Language Models (LLMs) have significantly impacted our lives. Despite understanding their internal structure, these models remain a focal point for scientists who often liken them to a “black box”. The final result depends not only on the LLM’s design but also on its training and the data used for training.
While scientists find research opportunities, end-users are primarily interested in two things: speed and quality. These criteria play a crucial role in the selection process. To accurately compare two LLMs, many seemingly unrelated factors need to be standardized.
The equipment used for interference and the software environment, including the operating system, driver versions, and software packages, have the most significant impact. It’s essential to select an LLM version that operates on various equipment and choose a speed metric that’s easily comprehensible.
We selected ‘tokens per second’ (tokens/s) as this metric. It’s important to note that a token ≠ a word. The LLM breaks words into simpler components, typical of a specific language, referred to as tokens.
The statistical predictability of the next character varies across languages, so tokenization will differ. For instance, in English, approximately 100 tokens are derived from every 75 words. In languages using the Cyrillic alphabet, the number of tokens per word may be higher. So, 75 words in a Cyrillic language, like Russian, could equate to 120-150 tokens.
You can verify this using OpenAI’s Tokenizer tool. It shows how many tokens a text fragment is broken into, making ‘tokens per second’ a good indicator of an LLM’s natural language processing speed and performance.
Each test was conducted on the Ubuntu 22.04 LTS operating system with NVIDIA® drivers version 535.183.01 and the NVIDIA® CUDA® 12.5 Toolkit installed. Questions were formulated to assess the LLM’s quality and speed. The processing speed of each answer was recorded and will contribute to the average value for each tested configuration.
We began testing various GPUs, from the latest models to the older ones. A crucial condition for the test was that we measured the performance of only one GPU, even if the multiple ones were present in the server configuration. This is because the performance of a configuration with multiple GPUs depends on additional factors such as the presence of a high-speed interconnect between them (NVLink®).
In addition to speed, we also attempted to evaluate the quality of responses on a 5-point scale, where 5 represents the best outcome. This information is provided here for general understanding only. Each time, we’ll pose the same questions to the neural network and attempt to discern how accurately each one comprehends what the user wants from it.
Qwen 2
Recently, a team of developers from Alibaba Group presented the second version of their generative neural network Qwen. It understands 27 languages and is well optimized for them. Qwen 2 comes in different sizes to make it easy to deploy on any device (from highly resource-constrained embedded systems to a dedicated server with GPUs):
- 0.5B: suitable for IoT and embedded systems;
- 1.5B: an extended version for embedded systems, used where the capabilities of 0.5B will not be enough;
- 7B: medium-sized model, well suited for natural language processing;
- 57B: high-performance large model suitable for demanding applications;
- 72B: the ultimate Qwen 2 model, designed to solve the most complex problems and process large volumes of data.
Versions 0.5B and 1.5B were trained on datasets with a context length of 32K. Versions 7B and 72B were already trained on the 128K context. The compromise model 57B was trained on datasets with a context length of 64K. The creators position Qwen 2 as an analog of Llama 3 capable of solving the same problems, but much faster.
Llama 3
The third version of the generative neural network from the MetaAI Llama family was introduced in April 2024. It was released, unlike Qwen 2, in only two versions: 8B and 70B. These models were positioned as a universal tool for solving many problems in various cases. It continued the trend towards multilingualism and multimodality, while simultaneously becoming faster than the previous versions and supporting a longer context length.
The creators of Llama 3 tried to fine-tune the models to reduce the percentage of statistical hallucinations and increase the variety of answers. So Llama 3 is quite capable of giving practical advice, helping to write a business letter, or speculating on a topic specified by the user. The datasets on which Llama 3 models were trained had a context length of 128K and more than 5% included data in 30 languages. However, as stated in the press release, generation performance in English will be significantly higher than in any other language.
Comparison
NVIDIA® RTX™ A6000
Let’s start our speed measurements with the NVIDIA® RTX™ A6000 GPU, based on the Ampere architecture (not to be confused with the NVIDIA® RTX™ A6000 Ada). This card has very modest characteristics, but at the same time, it has 48 GB of VRAM, which allows it to operate with fairly large neural network models. Unfortunately, low clock speed and bandwidth are the reasons for the low inference speed of text LLMs.
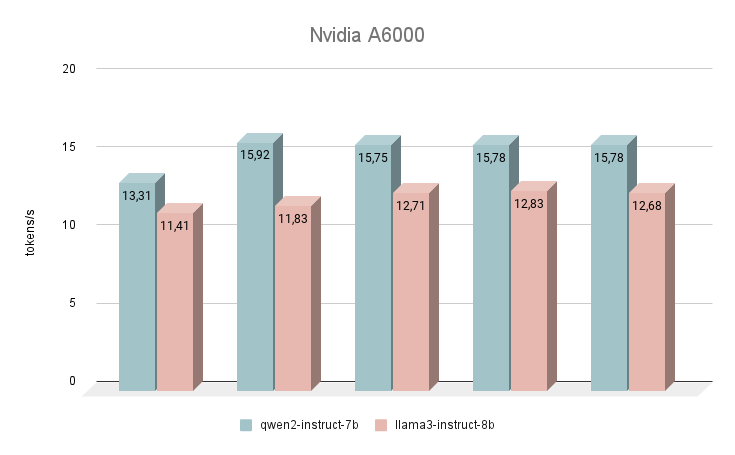
Immediately after launch, the Qwen 2 neural network began to outperform Llama 3. When answering the same questions, the average difference in speed was 24% in favor of Qwen 2. The speed of generating answers was in the range of 11-16 tokens per second. This is 2-3 times faster than trying to run generation even on a powerful CPU, but in our rating, this is the most modest result.
NVIDIA® RTX™ 3090
The next GPU is also built on the Ampere architecture, has 2 times less video memory, but at the same time, it operates at a higher frequency (19500 MHz versus 16000 Mhz). Video memory bandwidth is also higher (936.2 GB/s versus 768 GB/s). Both of these factors seriously increase the performance of the RTX™ 3090, even taking into account the fact that it has 256 fewer CUDA® cores.
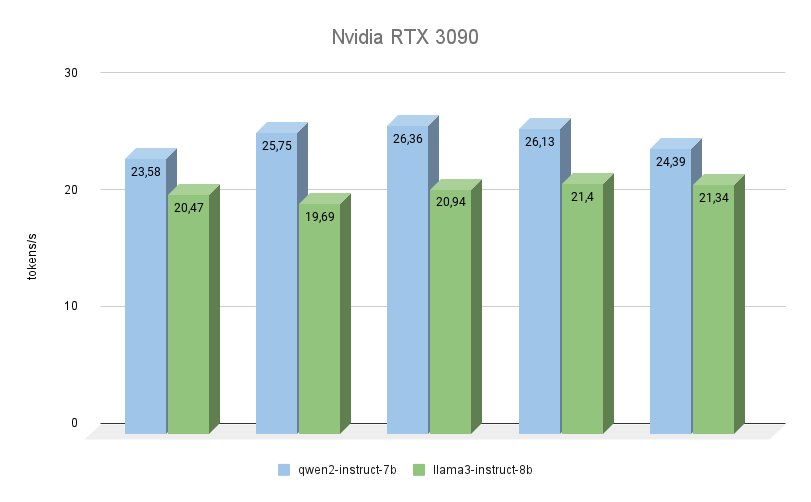
Here you can clearly see that Qwen 2 is much faster (up to 23%) than Llama 3 when performing the same tasks. Regarding the quality of generation, the multi language support of Qwen 3 is truly worthy of praise, and the model always answers in the same language in which the question was asked. With Llama 3, in this regard, it often happens that the model understands the question itself, but prefers to formulate answers in English.
NVIDIA® RTX™ 4090
Now the most interesting thing: let’s see how the NVIDIA® RTX™ 4090, built on the Ada Lovelace architecture, named after the English mathematician, Augusta Ada King, Countess of Lovelace, copes with the same task. She became famous for becoming the first programmer in the history of mankind, and at the time of writing her first program there was no assembled computer that could execute it. However, it was recognized that the algorithm described by Ada for calculating Bernoulli numbers was the first program in the world written to be played on a computer.
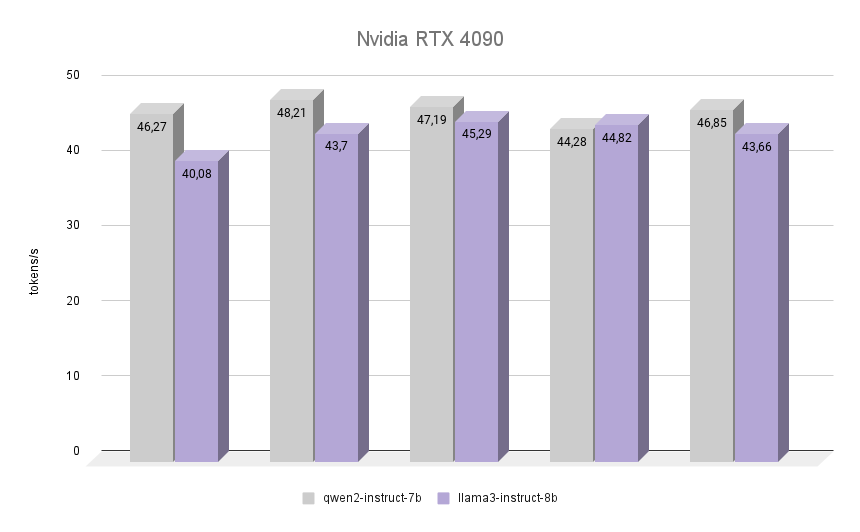
The graph clearly shows that the RTX™ 4090 coped with the inference of both models almost twice as fast. It’s interesting that in one of the iterations Llama 3 managed to outperform the Qwen 2 by 1.2%. However, taking into account the other iterations, Qwen 2 retained its leadership, remaining 7% faster than Llama 3. In all iterations, the quality of responses from both neural networks was high with a minimum number of hallucinations. The only defect is that in rare cases one or two Chinese characters were mixed into the answers, which did not in any way affect the overall meaning.
NVIDIA® RTX™ A40
The next NVIDIA® RTX™ A40 card, on which we ran similar tests, is again built on the Ampere architecture and has 48 GB of video memory on the motherboard. Compared to the RTX™ 3090, this memory is slightly faster (20000 MHz vs. 19500 MHz), but has lower bandwidth (695.8 GB/s versus 936.2 GB/s). The situation is compensated by the larger number of CUDA® cores (10752 versus 10496), which overall allows the RTX™ A40 to perform slightly faster than the RTX™ 3090.
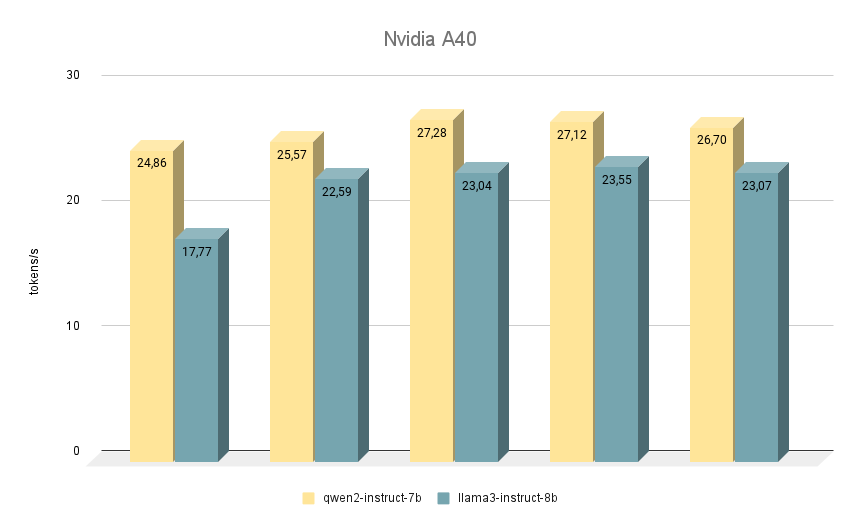
As for comparing the speed of models, here Qwen 2 is also ahead of Llama 3 in all iterations. When running on RTX™ A40, the difference in speed is about 15% with the same answers. In some tasks, Qwen 2 gave a little more important information, while Llama 3 was as specific as possible and gave examples. Despite this, everything has to be double-checked, since sometimes both models begin to produce controversial answers.
NVIDIA® L20
The last participant in our testing was the NVIDIA® L20. This GPU is built like the RTX™ 4090, on the Ada Lovelace architecture. This is a fairly new model, presented in the fall of 2023. On board, it has 48 GB of video memory and 11776 CUDA® cores. Memory bandwidth is lower than the RTX™ 4090 (864 GB/s versus 936.2 GB/s), as is the effective frequency. So the NVIDIA® L20 inference scores of both models will be closer to 3090 than 4090.
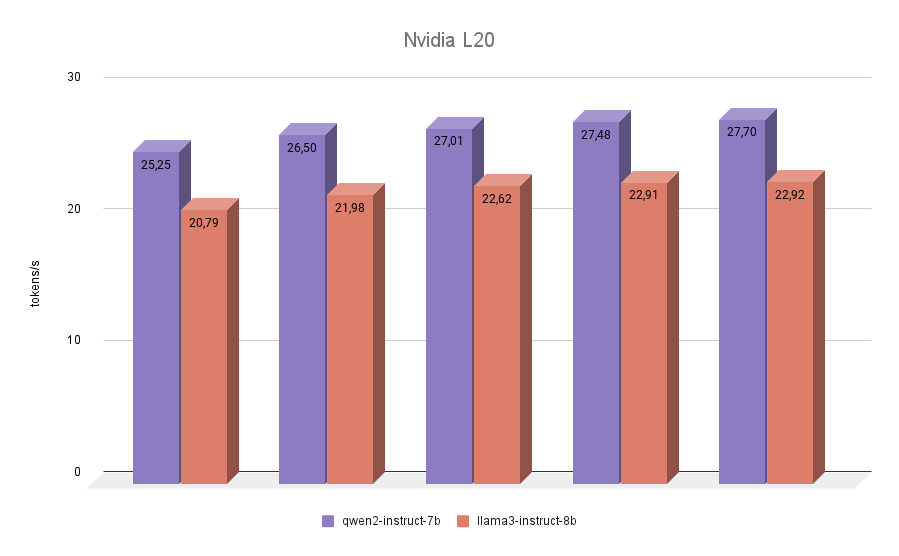
The final test didn’t bring any surprises. Qwen 2 turned out to be faster than Llama 3 in all iterations.
Conclusion
Let’s combine all the collected results into one chart. Qwen 2 was faster than Llama 3 from 7% to 24% depending on the used GPU. Based on this, we can clearly conclude that if you need to get high-speed inference from models such as Qwen 2 or Llama 3 on single-GPU configurations, then the undoubted leader will be the RTX™ 3090. A possible alternative could be the A40 or L20. But it’s not worth running the inference of these models on A6000 generation Ampere cards.

We deliberately didn’t mention cards with a smaller amount of video memory, for example, NVIDIA® RTX™ 2080Ti, in the tests, since it isn’t possible to fit the above-mentioned 7B or 8B models there without quantization. Well, the 1.5B model Qwen 2, unfortunately, doesn’t have high-quality answers and can’t serve as a full replacement for 7B.
See also:
Updated: 04.01.2026
Published: 20.01.2025




