





Qwen3-Coder: A Broken Paradigm

We’re used to thinking that open-source models always lag behind their commercial counterparts in quality. It may seem that they’re developed exclusively by enthusiasts who cannot afford to invest vast sums in creating high-quality datasets and training models on tens of thousands of modern GPUs.
It’s a different story when large corporations like OpenAI, Anthropic, or Meta take on the task. They not only have the resources but also the world’s top neural network specialists. Unfortunately, the models they create, especially the latest versions, are closed-source. Developers explain this by citing the risks of uncontrolled use and the need to ensure AI safety.
On one hand, their reasoning is understandable: many ethical questions remain unresolved, and the very nature of neural network models allows only indirect influence on the final output. On the other hand, keeping models closed and offering access only through their own API is also a solid business model.
Not all companies behave this way, however. For instance, the French company Mistral AI offers both commercial and open-source models, enabling researchers and enthusiasts to use them in their projects. But special attention should be paid to the achievements of Chinese companies, most of which build open-weight and open-source models capable of seriously competing with proprietary solutions.
DeepSeek, Qwen3, and Kimi K2
The first major breakthrough came with DeepSeek-V3. This multimodal language model from DeepSeek AI was developed using the Mixture of Experts (MoE) approach and impressive 671B parameters, with 37B most relevant ones activated for each token. Most importantly, all its components (model weights, inference code, and training pipelines) were released openly.
This instantly made it one of the most attractive LLMs for AI application developers, and researchers alike. The next headline-grabber was DeepSeek-R1 - the first open-source reasoning model. On its release day, it rattled the U.S. stock market after its developers claimed that training such an advanced model had cost only $6 million.
While the hype around DeepSeek eventually cooled down, the next releases were no less important for the global AI industry. We’re talking, of course, about Qwen 3. We covered its features in detail in our What's new in Qwen 3 review, so we won’t linger on it here. Soon after, another player appeared: Kimi K2 from Moonshot AI.
With its MoE architecture, 1T parameters (32B activated per token), and open-source code, Kimi K2 quickly drew community attention. Rather than focusing on reasoning, Moonshot AI aimed for state of the art performance in mathematics, programming, and deep cross-disciplinary knowledge.
The ace up Kimi K2’s sleeve was its optimization for integration into AI agents. This network was literally designed to make full use of all available tools. It excels in tasks requiring not only code writing but also iterative testing at each development stage. However, it has weaknesses too, which we’ll discuss later.
Kimi K2 is a large language model in every sense. Running the full-size version requires ~2 TB of VRAM (FP8: ~1 TB). For obvious reasons, this isn’t something you can do at home, and even many GPU servers won’t handle it. The model needs at least 8 NVIDIA® H200 accelerators. Quantized versions can help, but at a noticeable cost to accuracy.
Qwen3-Coder
Seeing Moonshot AI’s success, Alibaba developed its own Kimi K2-like model, but with significant advantages that we’ll discuss shortly. Initially, it was released in two versions:
- Qwen3-Coder-480B-A35B-Instruct (~250 GB VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 GB VRAM)
A few days later, smaller models without the reasoning mechanism appeared, requiring far less VRAM:
- Qwen3-Coder-30B-A3B-Instruct (~32 GB VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 GB VRAM)
Qwen3-Coder was designed for integration with development tools. It includes a special parser for function calls (qwen3coder_tool_parser.py, analogous to OpenAI’s function calling). Alongside the model, a console utility was released, capable of taste ranging from code compilation to querying a knowledge base. This idea isn’t new, essentially it’s heavily reworked extension of Anthropic’s Gemini code app.
The model is compatible with the OpenAI API, allowing it to be deployed locally or on a remote server and connected to most systems that support this API. This includes both ready-made client apps and machine learning libraries. This makes it viable not only for the B2C but also for the B2B segment, offering a seamless drop-in replacement for OpenAI’s product without any changes to application logic.
One of its most in-demand features is extended context length. By default, it supports 256k tokens but can be increased to 1M using the YaRN (Yet another RoPe extensioN) mechanism. Modern LLMs are typically trained on short datasets (2k–8k tokens), and large context lengths can cause them to lose track of earlier content.
YaRN is an elegant “trick” that makes the model think it’s working with its usual short sequences while actually processing much longer ones. The key idea is to “stretch” or “dilate” the positional space while preserving the mathematical structure the model expects. This allows effective processing of sequences tens of thousands of tokens long without retraining or extra memory required by traditional context extension methods.
Downloading and Running Inference
Make sure you’ve installed CUDA® beforehand, either using NVIDIA®’s official instructions or the Install CUDA® toolkit in Linux guide. To check for the required compiler:
nvcc --versionExpected output:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
If you get:
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
you need to add the CUDA® binaries to your system’s $PATH.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHThis is a temporary solution. For permanent edit ~/.bashrc and add the same two lines at the end.
Now, prepare your system for managing virtual environments. You can use Python’s built-in venv or the more advanced Miniforge. Assuming Miniforge is installed:
conda create -n venv python=3.10conda activate venvInstall PyTorch with CUDA® support matching your system:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124Then install the essential libraries:
- Transformers – Hugging Face’s main model library
- Accelerate – enables multi-GPU inference
- HuggingFace Hub – for downloading/uploading models & datasets
- Safetensors – safe model weight format
- vLLM – recommended inference library for Qwen
pip install transformers accelerate huggingface_hub safetensors vllmDownload the model:
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BRun inference with tensor parallelism (splitting layer tensors across GPUs, for example 8):
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000This launches the vLLM OpenAI API Server.
Testing and Integration
cURL
Install jq for pretty-printing JSON:
sudo apt -y install jqTest the server:
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
To integrate with Visual Studio Code, install the Continue extension and add to config.yaml:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply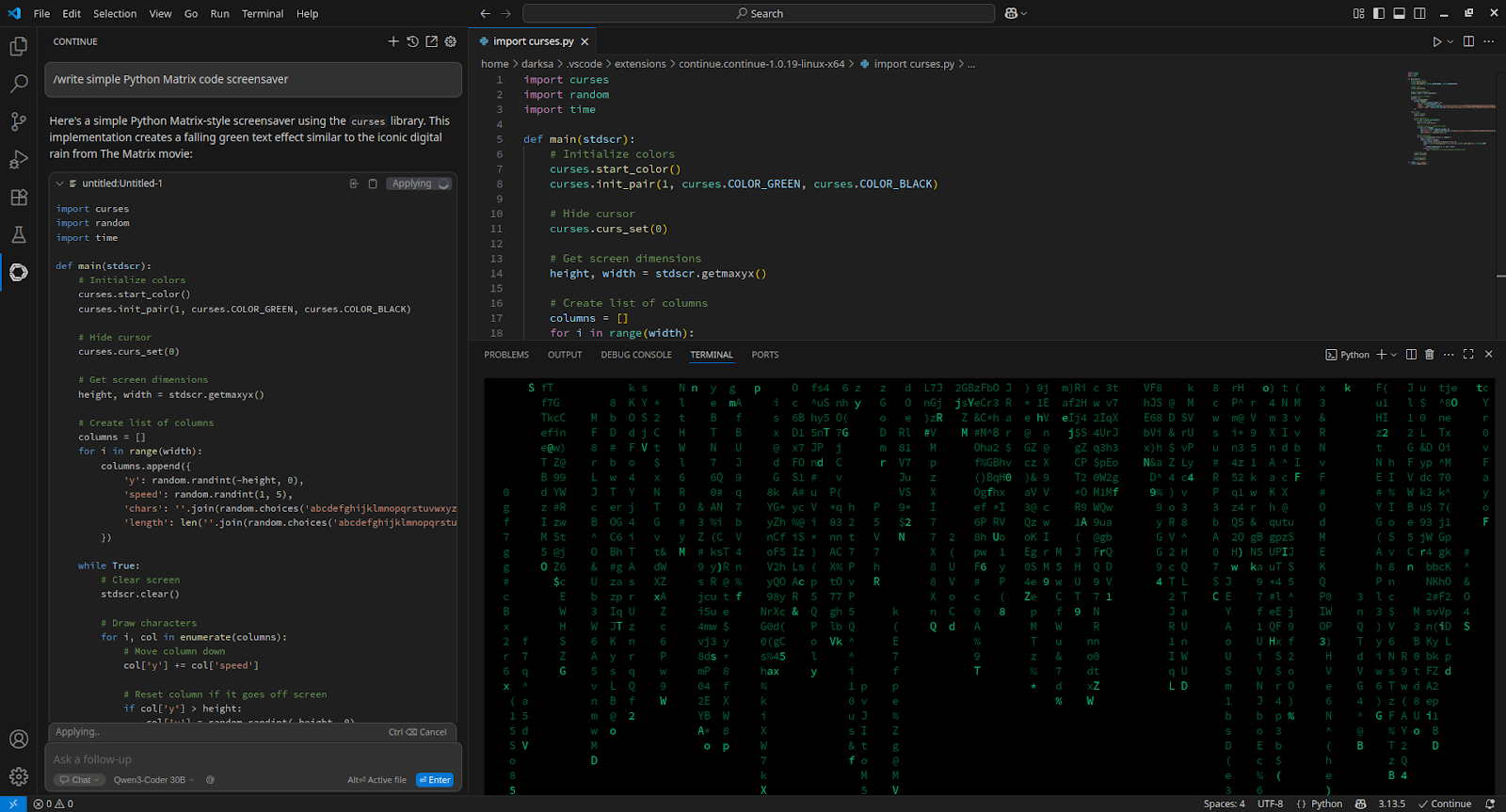
Qwen-Agent
For a GUI-based setup with Qwen-Agent (including RAG, MCP, and code interpreter):
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Open the nano editor:
nano script.pyExample Python script to launch Qwen-Agent with a Gradio WebUI:
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Run the script:
python script.pyThe server will be available at: http://127.0.0.1:7860
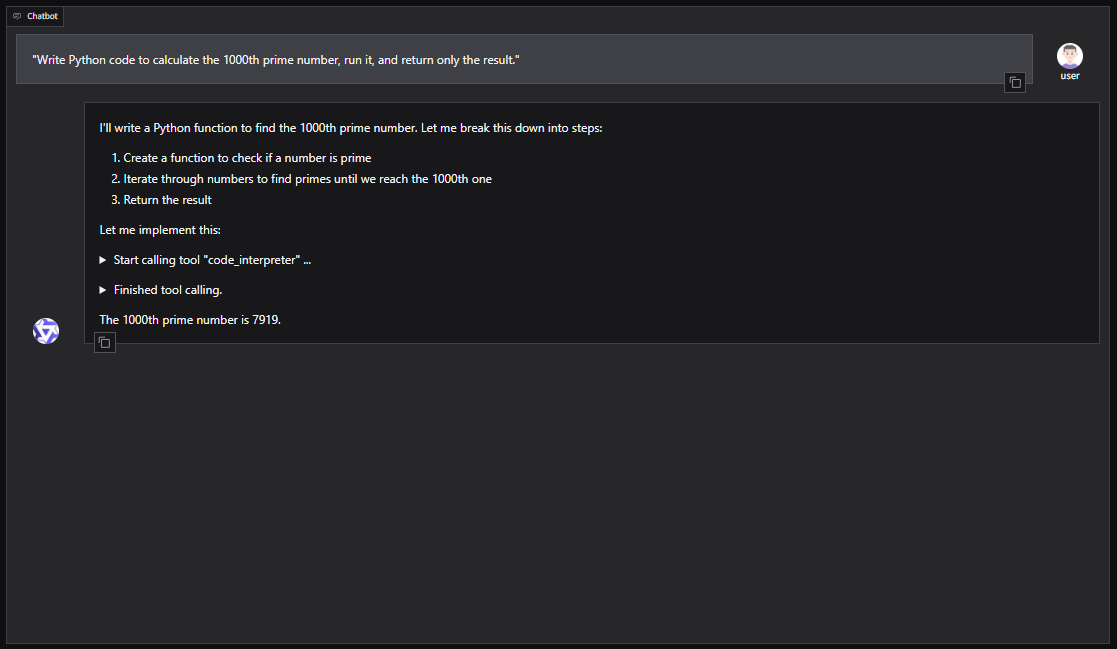
You can also integrate Qwen3-Coder into agent frameworks like CrewAI for automating complex tasks with toolsets such as web search or vector database memory.
See also:
Updated: 04.01.2026
Published: 12.08.2025




