





What is Knowledge Distillation
Large Language Models (LLMs) have become an integral part of our lives through their unique capabilities. They comprehend context and generate coherent, extensive texts based on it. They can process and respond in any language while considering the cultural nuances of each.
LLMs excel at complex problem-solving, programming, maintaining conversations, and more. This versatility comes from processing vast amounts of training data, hence the term "large". These models can contain tens or hundreds of billions of parameters, making them resource-intensive for everyday use.
Training is the most demanding process. Neural network models learn by processing enormous datasets, adjusting their internal "weights" to form stable connections between neurons. These connections store knowledge that the trained neural network can later use on end devices.
However, most end devices lack the necessary computing power to run these models. For instance, running the full version of Llama 2 (70B parameters) requires a GPU with 48 GB of video memory, hardware that few users have at home, let alone on mobile devices.
Consequently, most modern neural networks operate in cloud infrastructure rather than on portable devices, which access them through APIs. Still, device manufacturers are making progress in two ways: equipping devices with specialized computing units like NPUs, and developing methods to improve the performance of compact neural network models.
Reducing the size
Cut off the excess
Quantization is the first and most effective method for reducing neural network size. Neural network weights typically use 32-bit floating point numbers, but we can shrink them by changing this format. Using 8-bit values (or even binary ones in some cases) can reduce the network's size tenfold, though this significantly decreases answer accuracy.
Pruning is another approach, which removes unimportant connections in the neural network. This process works during both training and with completed networks. Beyond just connections, pruning can remove neurons or entire layers. This reduction in parameters and connections leads to lower memory requirements.
Matrix or tensor decomposition is the third common size-reduction technique. Breaking down one large matrix into a product of three smaller matrices reduces the total parameters while maintaining quality. This can shrink the network's size by dozens of times. Tensor decomposition offers even better results, though it requires more hyperparameters.
While these methods effectively reduce size, they all face the challenge of quality loss. Large compressed models outperform their smaller, uncompressed counterparts, but each compression risks reducing answer accuracy. Knowledge distillation represents an interesting attempt to balance quality with size.
Let’s try it together
Knowledge distillation is best explained through the analogy of a student and teacher. While students learn, teachers teach and also continuously update their existing knowledge. When both encounter new knowledge, the teacher has an advantage, they can draw upon their broad knowledge from other areas, while the student lacks this foundation yet.
This principle applies to neural networks. When training two neural networks of the same type but different sizes on identical data, the larger network typically performs better. Its greater capacity for "knowledge" enables more accurate responses than its smaller counterpart. This raises an interesting possibility: why not train the smaller network not just on the dataset, but also on the more accurate outputs of the larger network?
This process is knowledge distillation: a form of supervised learning where a smaller model learns to replicate the predictions of a larger one. While this technique helps offset the quality loss from reducing neural network size, it does require extra computational resources and training time.
Software and logic
With the theoretical foundation now clear, let's examine the process from a technical perspective. We'll begin with software tools that can guide you through the training and knowledge distillation stages.
Python, along with the TorchTune library from the PyTorch ecosystem, offers the simplest approach for studying and fine-tuning large language models. Here's how the application works:
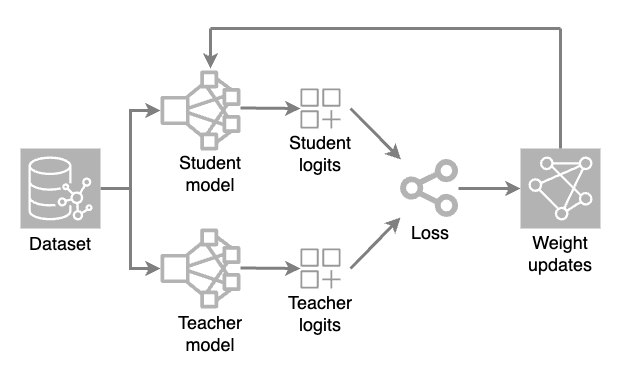
Two models are loaded: a full model (teacher) and a reduced model (student). During each training iteration, the teacher model generates high-temperature predictions while the student model processes the dataset to make its own predictions.
Both models' raw output values (logits) are evaluated through a loss function (a numerical measure of how much a prediction deviates from the correct value). Weight adjustments are then applied to the student model through backpropagation. This enables the smaller model to learn and replicate the teacher model's predictions.
The primary configuration file in the application code is called a recipe. This file stores all distillation parameters and settings, making experiments reproducible and allowing researchers to track how different parameters influence the final outcome.
When selecting parameter values and iteration counts, maintaining balance is crucial. A model that's distilled too much may lose its ability to recognize subtle details and context, defaulting to templated responses. While perfect balance is nearly impossible to achieve, careful monitoring of the distillation process can substantially improve the prediction quality of even modest neural network models.
It is also worth paying attention to monitoring during the training process. This will help to identify problems in time and promptly correct them. For this, you can use the TensorBoard tool. It integrates seamlessly into PyTorch projects and allows you to visually evaluate many metrics, such as accuracy and losses. Moreover, it allows you to build a model graph, track memory usage and execution time of operations.
Conclusion
Knowledge distillation is an effective method for optimizing neural networks to improve compact models. It works best when balancing performance with answer quality is essential.
Though knowledge distillation requires careful monitoring, its results can be remarkable. Models become much smaller while maintaining prediction quality, and they perform better with fewer computing resources.
When planned well with appropriate parameters, knowledge distillation serves as a key tool for creating compact neural networks without sacrificing quality.
See also:
Updated: 04.01.2026
Published: 23.01.2025




