





DeepSeek-R1: future of LLMs

While generative neural networks have been developing rapidly, their progress in recent years has remained fairly steady. This changed with the arrival of DeepSeek, a Chinese neural network that not only impacted the stock market but also captured the attention of developers and researchers worldwide. In contrast to other major projects, DeepSeek’s code was released under the permissive MIT license. This move towards open source earned praise from the community, who eagerly began exploring the new model’s capabilities.
The most impressive aspect was that training this new neural network reportedly cost 20 times less than competitors offering similar quality. The model required just 55 days and $5.6 million to train. When DeepSeek was released, it triggered one of the largest single-day drops in US stock market history. Though markets eventually stabilized, the impact was significant.
This article will examine how accurately media headlines reflect reality and explore which LeaderGPU configurations are suitable for installing this neural network yourself.
Architectural features
DeepSeek has chosen a path of maximum optimization, unsurprising given China’s U.S. export restrictions. These restrictions prevent the country from officially using the most advanced GPU models for AI development.
The model employs Multi Token Prediction (MTP) technology, which predicts multiple tokens in a single inference step instead of just one. This works through parallel token decoding combined with special masked layers that maintain autoregressivity.
MTP testing has shown remarkable results, increasing generation speeds by 2-4 times compared to traditional methods. The technology’s excellent scalability makes it valuable for current and future natural language processing applications.
The Multi-Head Latent Attention (MLA) model features an enhanced attention mechanism. As the model builds long chains of reasoning, it maintains focused attention on the context at each stage. This enhancement improves its handling of abstract concepts and text dependencies.
MLA’s key feature is its ability to dynamically adjust attention weights across different abstraction levels. When processing complex queries, MLA examines data from multiple perspectives: word meanings, sentence structures, and overall context. These perspectives form distinct layers that influence the final output. To maintain clarity, MLA carefully balances each layer’s impact while staying focused on the primary task.
DeepSeek’s developers incorporated Mixture of Experts (MoE) technology into the model. It contains 256 pre-trained expert neural networks, each specialized for different tasks. The system activates 8 of these networks for each token input, enabling efficient data processing without increasing computational costs.
In the full model with 671b parameters, only 37b are activated for each token. The model intelligently selects the most relevant parameters for processing each incoming token. This efficient optimization saves computational resources while maintaining high performance.
A crucial feature of any neural network chatbot is its context window length. Llama 2 has a context limit of 4,096 tokens, GPT-3.5 handles 16,284 tokens, while GPT-4 and DeepSeek can process up to 128,000 tokens (about 100,000 words, equivalent to 300 pages of typewritten text).
R - stands for Reasoning
DeepSeek-R1 has acquired a reasoning mechanism similar to OpenAI o1, enabling it to handle complex tasks more efficiently and accurately. Instead of providing immediate answers, the model expands the context by generating step-by-step reasoning in small paragraphs. This approach enhances the neural network’s ability to identify complex data relationships, resulting in more comprehensive and precise answers.
When faced with a complex task, DeepSeek uses its reasoning mechanism to break down the problem into components and analyze each one separately. The model then synthesizes these findings to generate a user response. While this appears to be an ideal approach for neural networks, it comes with significant challenges.
All modern LLMs share a concerning trait - artificial hallucinations. When presented with a question it cannot answer, instead of acknowledging its limitations, the model might generate fictional answers supported by made-up facts.
When applied to a reasoning neural network, these hallucinations could compromise the thought process by basing conclusions on fictional rather than factual information. This could lead to incorrect conclusions - a challenge that neural network researchers and developers will need to address in the future.
VRAM consumption
Let’s explore how to run and test DeepSeek R1 on a dedicated server, focusing on the GPU video memory requirements.
| Model | VRAM (Mb) | Model size (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| deepseek-r1:8b | 6,482 | 4.9 |
| deepseek-r1:14b | 10,880 | 9 |
| deepseek-r1:32b | 21,758 | 20 |
| deepseek-r1:70b | 39,284 | 43 |
| deepseek-r1:671b | 470,091 | 404 |
The first three options (1.5b, 7b, 8b) are basic models that can handle most tasks efficiently. These models run smoothly on any consumer GPU with 6-8 GB of video memory. The mid-tier versions (14b and 32b) are ideal for professional tasks but require more VRAM. The largest models (70b and 671b) require specialized GPUs and are primarily used for research and industrial applications.
Server selection
To help you choose a server for DeepSeek inference, here are the ideal LeaderGPU configurations for each model group:
1.5b / 7b / 8b / 14b / 32b / 70b
For this group, any server with the following GPU types will be suitable. Most LeaderGPU servers will run these neural networks without any issues. Performance will mainly depend on the number of CUDA® cores. We recommend servers with multiple GPUs, such as:
671b
Now for the most challenging case: how do you run inference on a model with a 404 GB base size? This means approximately 470 GB of video memory will be required. LeaderGPU offers multiple configurations with the following GPUs capable of handling this load:
Both configurations handle the model load efficiently, distributing it evenly across multiple GPUs. For example, this is what a server with 8xH100 looks like after loading the deepseek-r1:671b model:
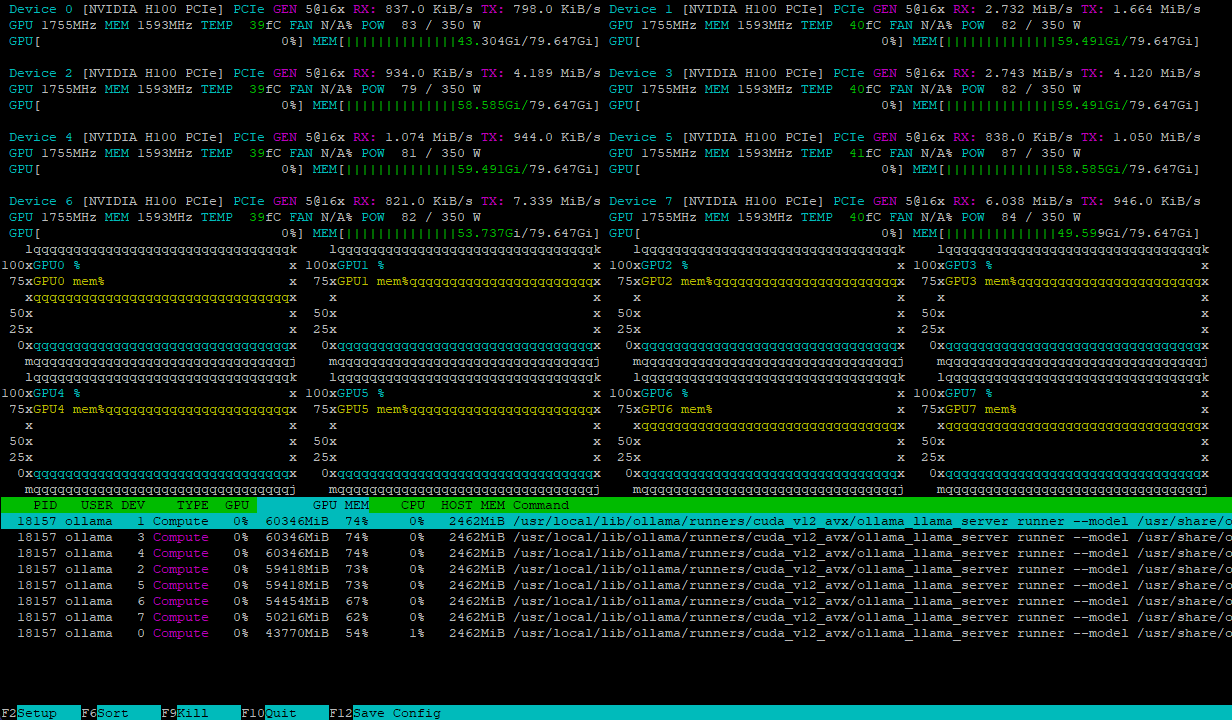
The computational load balances dynamically across GPUs, while high-speed NVLink® interconnects prevent data exchange bottlenecks, ensuring maximum performance.
Conclusion
DeepSeek-R1 combines many innovative technologies like Multi Token Prediction, Multi-Head Latent Attention, and Mixture of Experts into one significant model. This open-source software demonstrates that LLMs can be developed more efficiently with fewer computational resources. The model has various versions from smaller 1.5b to huge 671b which require specialized hardware with multiple high-end GPUs working in parallel.
By renting a server from LeaderGPU for DeepSeek-R1 inference, you get a wide range of configurations, reliability, and fault tolerance. Our technical support team will help you with any problems or questions, while the automatic operating system installation reduces deployment time.
Choose your LeaderGPU server and discover the possibilities that open up when using modern neural network models. If you have any questions, don’t hesitate to ask them in our chat or email.
Updated: 04.01.2026
Published: 19.02.2025




